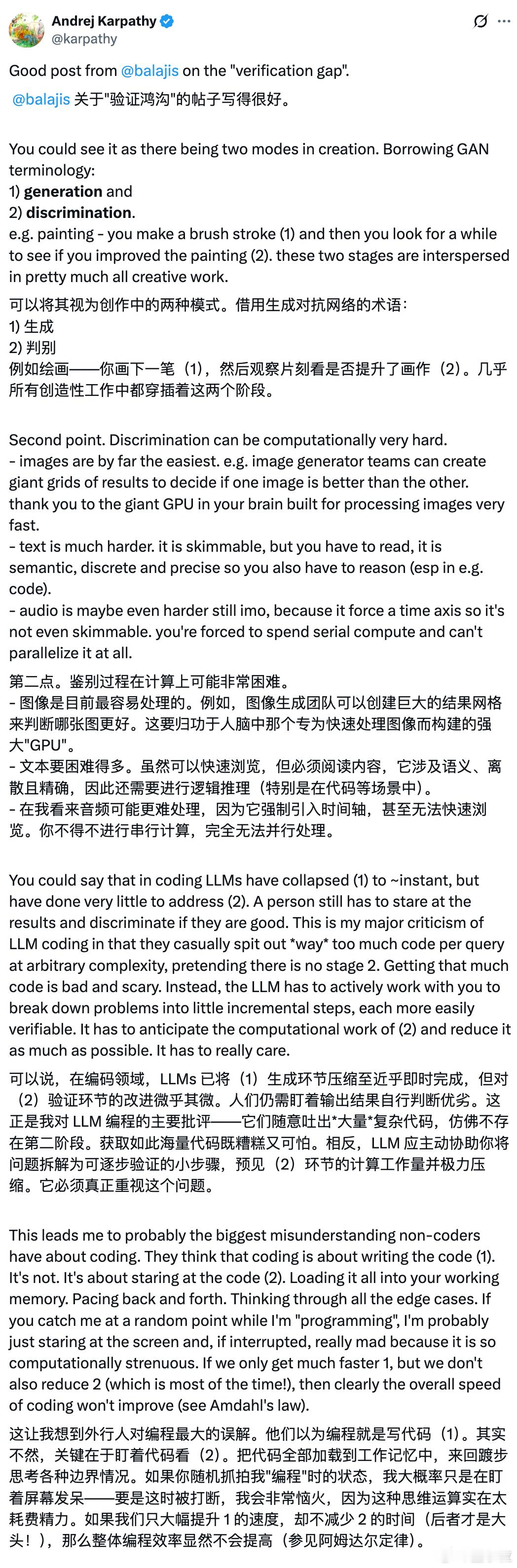
使用AI的核心困境是如何验证输出卡帕西谈AI输出验证困境
相信大家对怎么给AI下指令都有经验了,但怎么验证AI给出的结果是否靠谱,却常常让人犯难。
前a16z知名投资人Balaji Srinivasan在X上说了一句大实话:对于用户来说,现在使用AI的核心问题已经不是怎么写好提示词,而是如何低成本验证AI模型的输出。【图1】
和研究怎么输入文字的提示词工程相比,验证 AI 的输出要复杂得多:
图片、视频、网页界面,直接用眼睛看就能判断好坏。但像代码或文字这类内容,想纠正错误就得有专业知识了。
比如写论文,AI就常常编造文献和引用来源,需要用户自行核对引用来源。最近很火的氛围编程,也需要你一步步调试运行过程,才能放心用到实际项目中。
大神卡帕西也转发认可了这一“验证鸿沟”,他借用生成对抗网络的两个术语,把AI的创作过程分为两个阶段:生成和判别。【图2】
简单来说,用AI创作就像画画:你让AI画一笔(生成),然后你得判断这一笔画得好不好(判别)。
卡帕西也认同这个“判别”过程可能极其困难:
- 图像最简单:因为我们人脑天生就是处理图像的高手,图像生成团队可以做大量的图来对比好坏。
- 文本困难得多:虽然可以快速阅览,但总归是需要阅读的;而且因为它有语义、有逻辑,验证时还得进行逻辑推理,尤其是代码。
- 音频可能更棘手:音频内容必须按时间顺序播放,不能像文字那样跳着看。你只能“串行”处理,根本无法“并行”快速检查。
在编程领域,AI已经把写代码(生成)的过程压缩到了几乎瞬间完成。但在 “判别” 方面,AI几乎没有任何突破,程序员们还得瞪大眼睛盯着结果,亲自去检查。
理想中的AI应该能主动把任务分解成一个个可以验证的步骤,并且预估到“判别”阶段的难度,尽量帮程序员减少工作量。但现在的AI只会一股脑地吐出大量复杂代码,反而给程序员带来了更多负担。
如果AI只是加速了“生成”阶段,而没有缩短占用大部分时间的“判别”阶段,那么编程的整体效率根本不会提高,这就像著名的阿姆达尔定律说的那样。
对此,你怎么看?