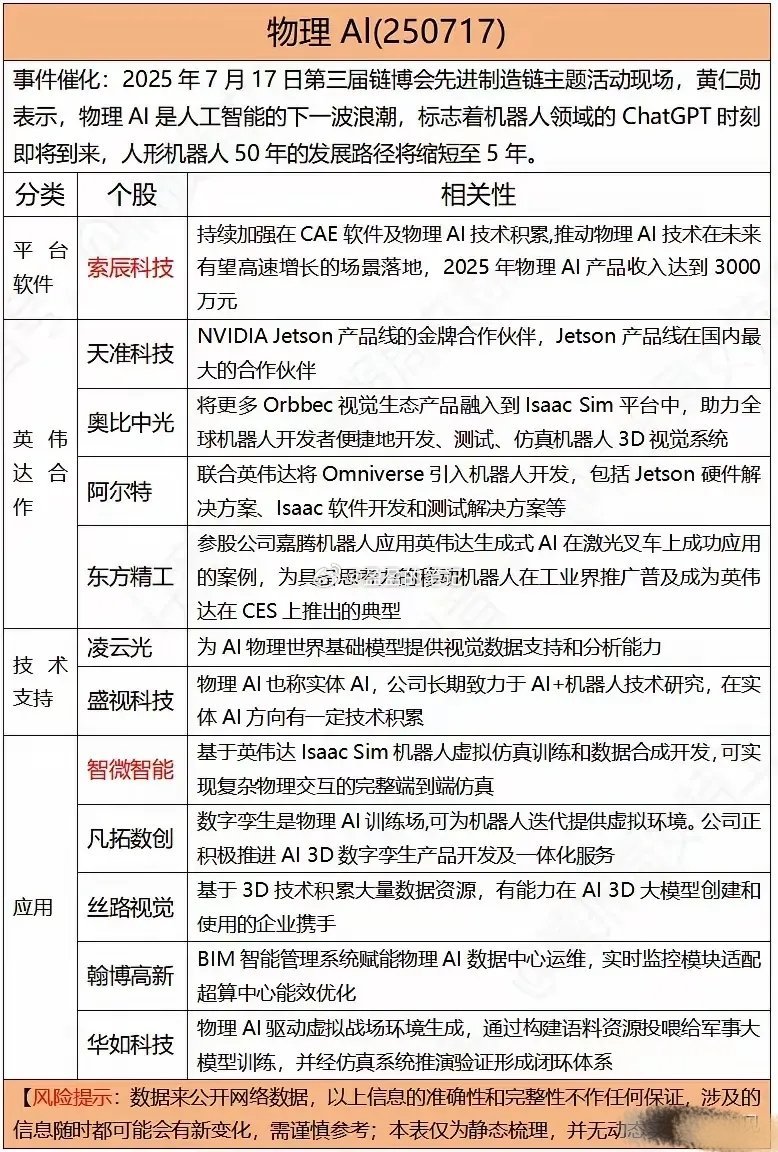
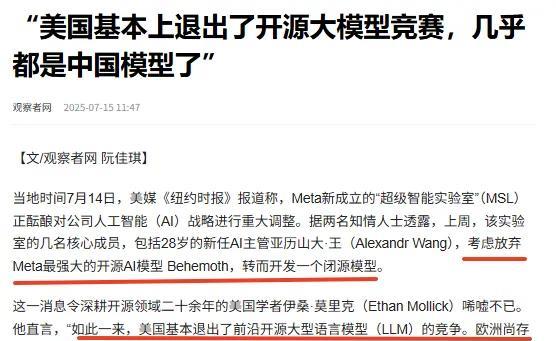
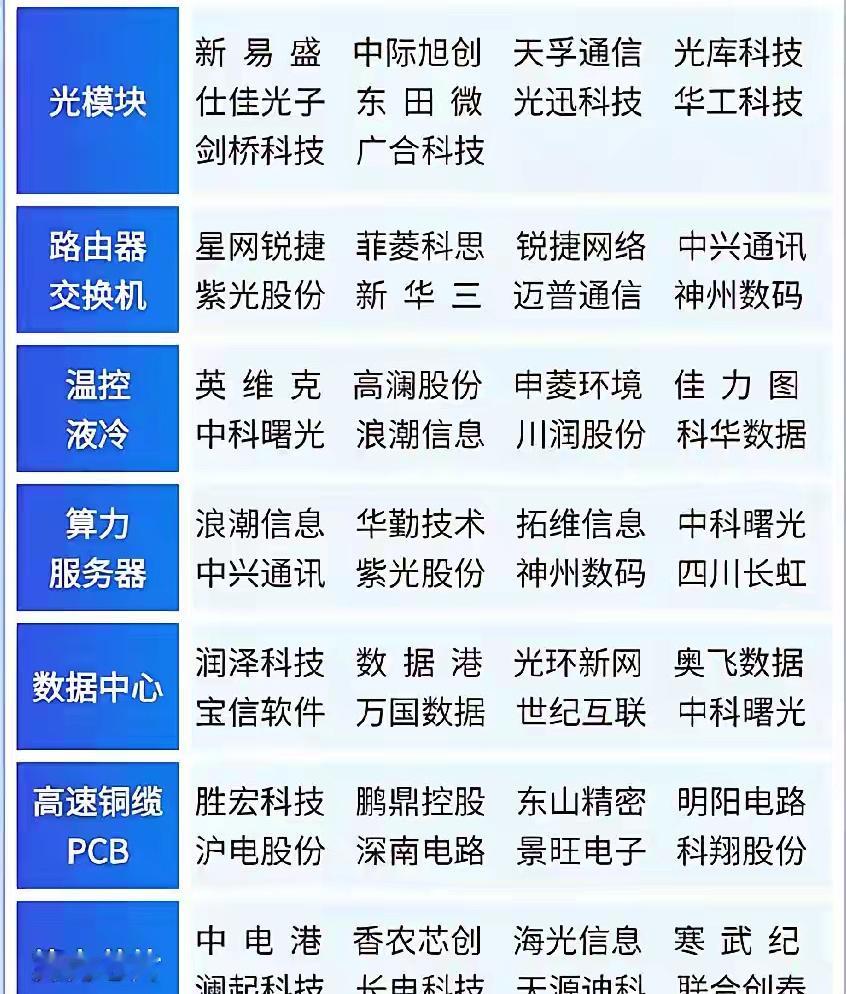
潮新闻客户端执笔沈吟叶诗蕾
7月以来,从国家互联网信息办公室、国家数据局等联合主办2025全球数字经济大会,到中国通信标准化协会大数据技术标准推进委员会牵头、联合行业专家共同编制《高质量数据集实践指南(1.0)》正式发布……高质量数据集的热度持续高企。
什么是高质量数据集?
它是经过处理,可直接用于AI模型训练、能有效提升模型性能的数据集合,储存着AI所需的高价值、高密度、标准化的“粮食”。

都说巧妇难为无米之炊。和人一样,AI同样需要大量的数据作为“粮食”,来进行模型训练和深度学习。可以说,没有高质量数据,就“养”不出高质量的人工智能。
这些经过加工分类的高质量数据集,在AI时代撬动的能量不可小觑。
高质量数据集,为何重要?
近两年,我国的高质量数据集建设按下了“加速键”。
2023年底,国家数据局等17部门联合印发了《“数据要素×”三年行动计划(2024—2026年)》,提出推动科研机构、龙头企业等开展行业共性数据资源库建设,打造高质量人工智能大模型训练数据集。
去年底,国家发展改革委等部门出台《关于促进数据产业高质量发展的指导意见》,首次明确提出“高质量数据集”,将其作为人工智能与实体经济融合的核心载体。随后一系列政策相继发布。
今年2月,高质量数据集建设工作启动会在北京召开,27个部门参会。会上明确提出积极推进落实“人工智能+”行动,推动高质量数据集建设,高效赋能行业发展……
“‘人工智能+’行动到哪里,高质量数据集的建设和推广就要到哪里。”国家数据局局长刘烈宏在中国发展高层论坛2025年年会上明确表示。
江苏、贵州、上海、广东、浙江等多地也纷纷出台激励政策。为何从国家到地方都如此重视高质量数据集建设?

浙江数字化发展与治理研究中心主任、浙江大学管理学院教授刘渊告诉记者,没有高质量的数据就喂不出高质量的人工智能。原先很多人认为,高算力和高投入是发展人工智能唯一途径。但是DeepSeek等的出现,让越来越多从业者意识到,要高度重视数据质量与规模,高质量数据集成为人工智能发展的关键要素之一。
中国信息通信研究院副院长魏亮一针见血地指出,数据集的质量影响人工智能的“智商”。“数据之于大模型,就像石油之于汽车。海量原始数据需要经过‘炼化’形成高质量数据集,才能助力大模型精准学习数据特征与规律,有效提升其对不同场景和任务的适应能力。”
除了各级政府外,大模型科技企业、科研学术单位也纷纷发力高质量数据集。比如,阿里巴巴发布中文问答数据集;百度发布百度百科数据集、百度搜索数据集等。
国外也正聚焦这一领域发力。欧盟2022年就通过了《高价值数据集实施法案》。去年,华盛顿大学、SalesforceResearch和斯坦福大学等机构联合团队推出了MINT-1T数据集。它包含万亿token(大模型处理文本的基本单位),是截至目前最大的多模态开源数据集。经过验证,以这个数据集为基础预训练的模型,在视觉描述、视觉问答、多图像推理等方面取得了显著提升。
高质量数据与人工智能的结合,将进一步发挥数据和人工智能的倍增效应。这点无疑已经成为政府部门、行业从业人员、专家学者们的共识。
数据集如何影响我们
AI时代,高质量数据集的需求量、交易量激增。
记者在贵州大数据集团下属贵阳大数据交易所采访时获悉,去年至今,贵数所发布了939个高质量数据集,为区域高质量数据集产业生态的发展起到了良好的带头示范作用。
贵数所市场部产品总监李霖泽介绍,去年官网正式上线高质量数据集专区,短短一年时间,已聚集46家市场主体。专区目前已涵盖金融服务、气象服务、现代农业、工业制造、医疗健康、商贸流通等重点领域。
如何让质量有保障?“比如文本数据,我们要求结构清晰,没有乱码,且内容重复率比较低;而图像、视频等数据,除了分辨率要高,还要求有相对详细的标注,对每一条数据的场景描述尽可能完整和丰富。”李霖泽说。
用户只需轻点鼠标,即可按使用场景、获取方式精准检索所需的高质量数据集,就像是线上购物一样便捷。
贵数所高质量数据集上架的产品,其价值不仅体现在数量优势上,更在于多样性与系统性——涵盖文字、音频、图片、视频等多种模态,以及TTS(文本转语音)、OCR(光学字符识别)等跨模态数据。

在2025全球数字经济大会上,北京国际大数据交易所董事长李振军也透露:“去年开始,高质量数据集呈现了爆发式的增长态势,主要需求就是模型训练数据。2024年人工智能数据只占我们交易量的10%,现在累加起来已经接近80%,说明包括实际交易量都在呈现爆发式增长。”
据了解,北京国际大数据交易截至目前已为大模型提供覆盖32个行业475个数据集。今年1月至5月,北数所新增高质量数据产品152个,场内交易规模超4400万元,同比增长37.63%。
高质量数据集对行业发展而言,最显著的作用是降本增效。在贵州,高质量数据集的赋能正延伸至更广泛领域。
比如有客户提出,在建设电站时,需要非常详细的建设地风量、风速、风力数据,用来指导风力发电机的运转。“我们的专区里就有这样的产品,可以帮助客户搭建风机功率的预测模型。在未来一段时间内,能够产生的发电量是多少,并以此去调整相应的储电储能设备管理等。”李霖泽举例介绍。
未来,贵数所一方面将继续丰富高质量数据的供给,为更多大模型厂商等提供更多数据支持,另一方面计划引入第三方数据加工治理服务机构,把更多的原始数据进行清洗、治理、加工,变成可交付的“金首饰”(高质量数据集)。“我们希望形成良性循环,持续提升高质量数据集的供给能力和质量。”李霖泽说。
还需迈过几道坎
《高质量数据集实践指南(1.0)》中提到,目前我国高质量场景数据集存在较大供需缺口,产业还处于探索阶段。
多位从业人员、专家认为,目前主要是有三方面挑战。

一是数量不足,供需不匹配。“AI大模型技术的快速迭代,不仅带来对数据的海量需求,也对数据集的构建提出了更多挑战。训练AI大模型需要大规模、高质量、多模态的数据集。”浙江大学公共管理学院博士后李兴腾和同伴,专门对突破人工智能大模型的“数据瓶颈”问题进行过研究。李兴腾认为,AI技术的快速迭代,加剧数据供需矛盾,高质量数据短缺将成为制约AI技术发展的重要因素。
“各个大模型厂商训练大模型的侧重点、场景都不一样,面对的行业不一样、客户群体不同,他们对数据都会有定制化的需求。”李霖泽说。
二是标准缺失、质量参差。不少专家指出,目前,对于高质量数据集还没有统一衡量标准,不同行业、不同数据源的数据完整性和准确性可能参差不齐,这不仅会影响了大模型的训练效果,也容易造成训练资源的浪费。
三是开放和流通程度不够。当下,高质量数据集开放程度低,数据孤岛依然存在,很多企业更倾向于自采、自用,数据流通机制有待进一步完善。刘渊教授指出,仅有高质量的数据并不够,还需要构建开放协同的数据共享机制,同时完善数据安全治理。“只有在流通和使用过程中才能充分释放数据要素价值。我们要让数据‘供得出’‘流得动’‘用得好’,高质量数据集才能最大限度发挥作用。”
以上种种挑战,都制约着数据要素潜能的释放。当下,从国家和地方都在积极破题。
目前,国家数据局正在开展高质量数据集典型案例征集,面向20多个行业和领域。
国家数据局局长刘烈宏曾公开表示,将充分调动社会各方力量,积极推动高质量数据集建设,持续增加数据供给,推动“人工智能+”行动赋能千行百业,打造包容开放的创新环境。
国资委今年4月发布首批10余个行业、30项央企人工智能行业高质量数据集。
各地同样不甘示弱。湖北省数据局已征集发布两批35个高质量数据集,为湖北AI大模型产业发展提供“养料”;苏州市发布首批30个行业高质量数据集,涵盖工业制造、交通运输、金融服务等重点行业领域……
包括浙江在内的多地,纷纷明确建设高质量数据集的数量、激励机制等。
北京大力推动人工智能创新发展,指导发布1.6T高质量中文语料库,推动建设垂直领域数据集。
深圳去年底出台政策,每年发放最高5000万元“语料券”,促进人工智能语料数据开放共享和交易,鼓励企业通过数据交易平台购买语料数据进行大模型研发和应用,可给予最高200万元的资助。

杭州同样拿出真金白银,支持行业龙头企业推进高质量数据集建设。今年6月下旬新发布的《杭州市加快建设人工智能创新高地实施方案(2025年版)》,明确提出支持数据集及数据基础设施建设。
我们从杭州市数据资源管理局了解到,杭州支持企业和机构通过杭州数据开放平台向社会提供训练、验证、测试、语料等数据集,每年评选不超过5个高质量开放数据集,按照不超过实际投入的30%给予奖励,同一单位年度最高奖励100万元,高质量多模态开放数据集奖励最高可提升至200万元。此外,杭州还积极搭建行业高质量数据集的基础性平台,计划今年9月上线试运行。
在业内人士看来,医疗健康、金融服务行业的高质量数据,目前较为稀缺。当前,浙江正在积极推进数字政府2.0建设,在守护数据安全的基础上,有序推进医疗健康、文化旅游、具身智能等领域分行业试点,建好高质量数据集。
旺盛的市场需求,加上有力的政策推动,未来高质量数据集的用武之地将越来越多,赋能“千行百业”:在医疗领域,可以辅助诊断;在工业场景中,可监测预警安全问题、提前识别设备故障;在农业领域,可以支撑智慧农场……
我们相信,有了源源不断的优质“食材”,高质量数据集将在更多行业、更多场景中落地,真正成为人工智能的“燃料”、产业升级的“加速器”。