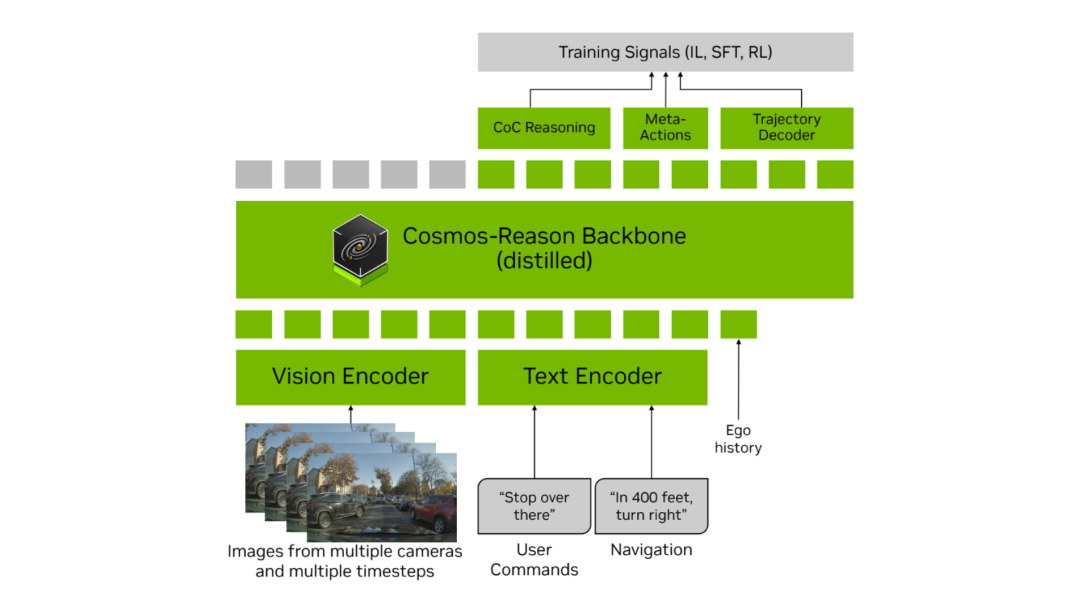
英伟达的下一代辅助驾驶模型架构,基于 VLA 的 Alpamayo-R1 也来了,按吴新宙的说法,这个模型加上英伟达 Thor 平台应该会在未来几年在 GTC 上官宣奔驰、Lucid 和 Stellantis 的部分车型上投产。
Alpamayo-R1 大致提出了 3 个问题,也都给了对应的解法。
- 1.传统端到端在极端场景下表现不佳;2. 推理和行为割裂。
这个没啥可说的,模仿学习只会模仿,但不会推理,一旦遇到罕见的复杂场景就容易挂。
第 2 个我相信很多国产 VLA 辅助驾驶用户是有共鸣的,很多时候你真对照着中控屏上 VLM 输出的思维链对比,发现 VLM 的思维链和控车的模型各干各的,其实没啥关系…
VLM 只生成文字的思维过程,和模型的实际规划无关。
Alpamayo-R1 的解法是首次提出因果链标注(Chain of Causation)数据集,每一段的数据不仅标注视觉信息,还会标出因果因素和驾驶决策,比如「因为右侧有施工车,所以此时应该减速向左变道」
英伟达采用人工 + GPT-5 自动标注 + 质量检查的混合方式,生成大规模、高质量的 CoC 数据集。
Alpamayo-R1 用上面的 CoC 数据集进行 SFT 监督微调,让模型学会解释「为什么要这么开车」。
然后用和 OpenAI o1、DeepSeek-R1 类似的方法,用可验证奖励机制,强化模型在推理和行为之间的一致性。
- 3. 车端参数量规模、实时性的矛盾。
这就更老生常谈了。Alpamayo-R1 的解法是用重新设计的 Vision Encoder,将 token 数量压缩了 10 - 20 倍,把模型延迟控制在 99 毫秒,这个还是挺厉害的。
模型参数量也从 0.5 B 增加到 7B,模型轨迹准确性提升了 11%。
从这些技术手段,尤其是最后追求参数量规模和低延迟,能看出虽然这本质上还是一个研究工作,但英伟达更重视在量产车上实际部署的效果了,这也和最近一段时间的新闻说英伟达增加对自动驾驶领域的投入、和 GTC 上的官宣是能对得上的。