不靠Transformer也能搞大模型比Transformer更快框架来了
不靠Transformer,也能搞出大模型!
Mamba新作:Mamba-3,一种不用注意力机制的语言模型。
它比Transformer更快、上下文更长、可扩展性更强。
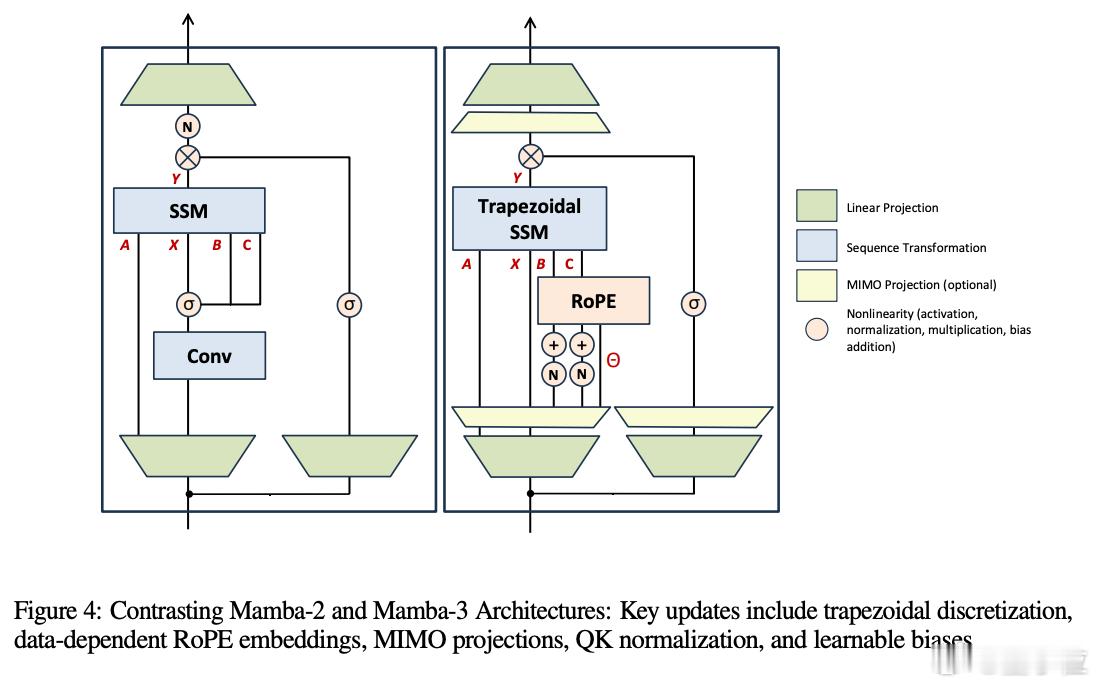
相比上一代,Mamba-3带来了三大核心升级:
- 用梯形积分替换传统的Euler方法,让模型对长序列的记忆更稳定;
- 隐状态引入复数计算,能处理像“奇偶性”这类带周期性的语言任务;
- 全新MIMO结构,可并行处理多条信息流,大大提高推理效率。
这些技术统称为SSM(State Space Model,状态空间模型)路线,是近年来被重新挖掘的旧概念。核心思想是:模型通过「记住过去」来理解语言,而不是像Transformer那样,每次都重新计算所有位置之间的关系。
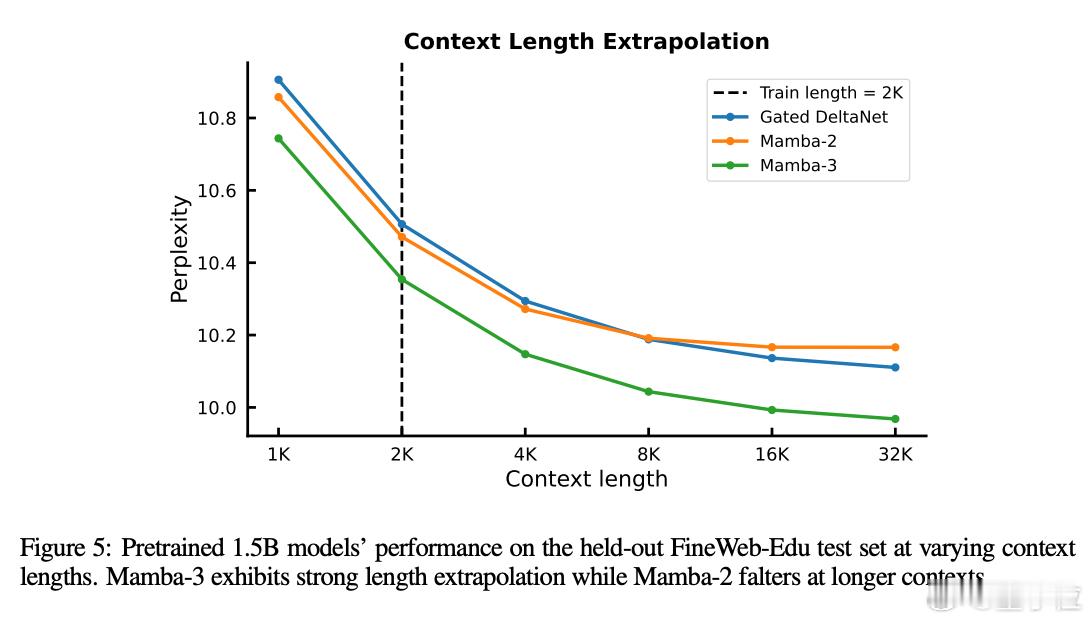
Mamba-3的实际表现也确实撑得起“升级”二字:
- 在TQA等多项语言任务中,精度超过Transformer和Mamba-2;
- 在复杂数学任务中(如括号匹配、奇偶判断),Mamba-3能100%正确,而Mamba-2直接挂掉;
- 推理速度快,硬件利用率更高,更适合边缘设备部署或需要实时响应的场景。
不过它也有短板。面对“非结构化”检索任务,比如开放问答,Mamba-3还是干不过Transformer,尤其是上下文非常模糊的情况。
Mamba-3像是一种轻量化替代方案,在保持推理效率的同时,补足了上一代SSM的能力短板,也能在某些任务上直接跑赢Transformer。
未来,研究者打算把Mamba和记忆增强系统结合,用外部检索来弥补“状态大小固定”的问题。
论文原文:openreview.net/pdf?id=HwCvaJOiCj