[CL]《Parallel-R1: Towards Parallel Thinking via Reinforcement Learning》T Zheng, H Zhang, W Yu, X Wang... [Tencent AI Lab Seattle] (2025)
大语言模型(LLM)推理能力迎来新突破:Parallel-R1,通过强化学习(RL)系统性培养“并行思维”策略,实现复杂数学任务的多路径思考与验证。
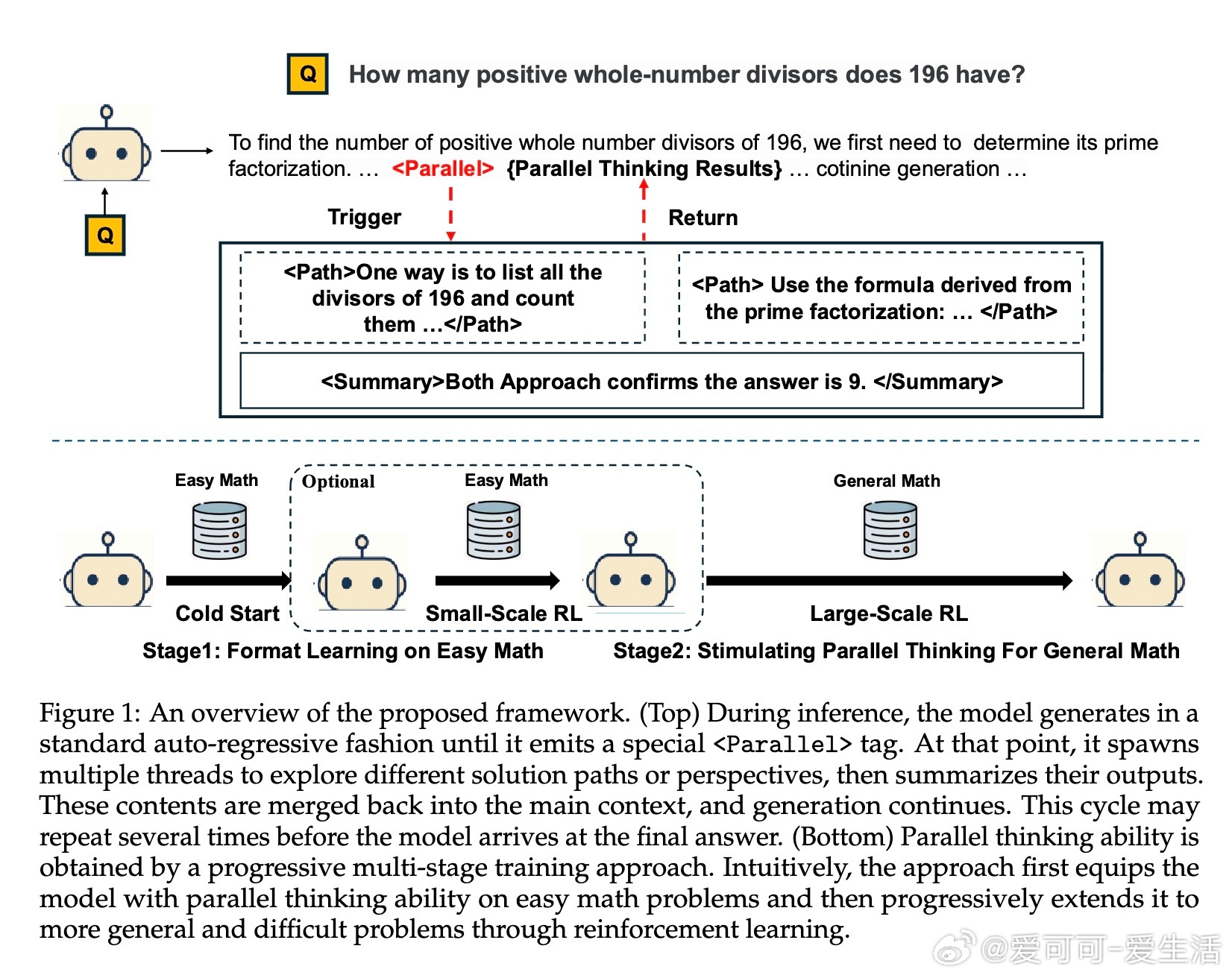
• 并行思维定义为关键推理步骤触发多线程探索,生成多条独立路径,再综合总结形成最终结论,模拟人类多角度验证思考模式。
• 采用“渐进式课程”训练策略:先用简单数学题(Parallel-GSM8K数据集)进行监督微调,教会模型并行思维格式;再转入强化学习,在更难的数学任务(DAPO等)中探索并泛化该能力。
• 设计独特奖励机制交替鼓励准确率与并行思维结构,平衡性能与并行使用率,避免极端优化导致性能下降。
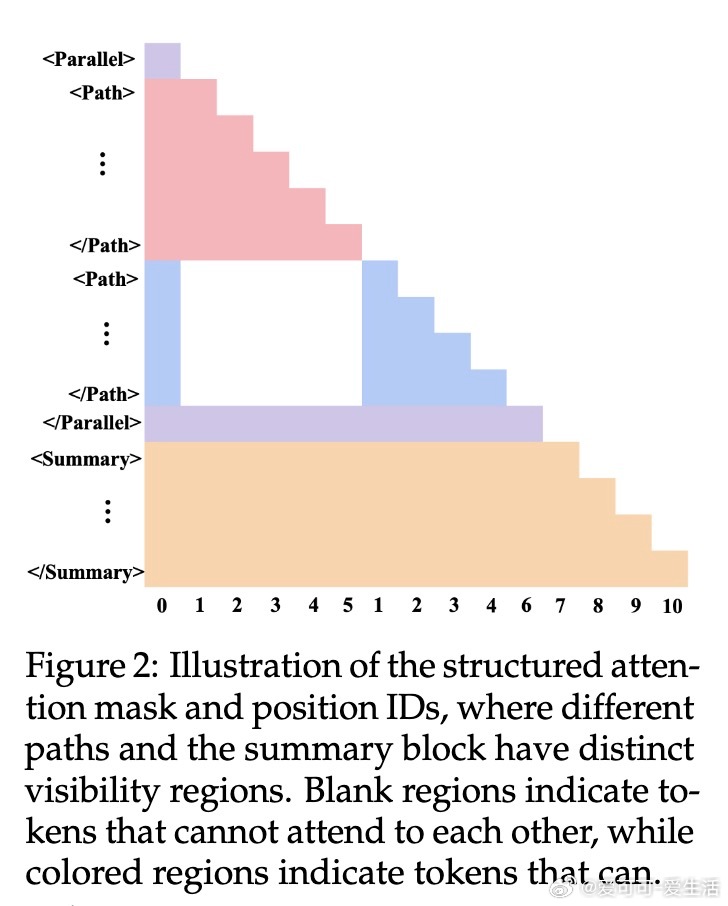
• 提出两种架构方案:无结构修改的“Parallel-R1-Seen”和引入路径隔离注意力掩码的“Parallel-R1-Unseen”,后者显著抑制路径信息泄露但训练泛化更具挑战。
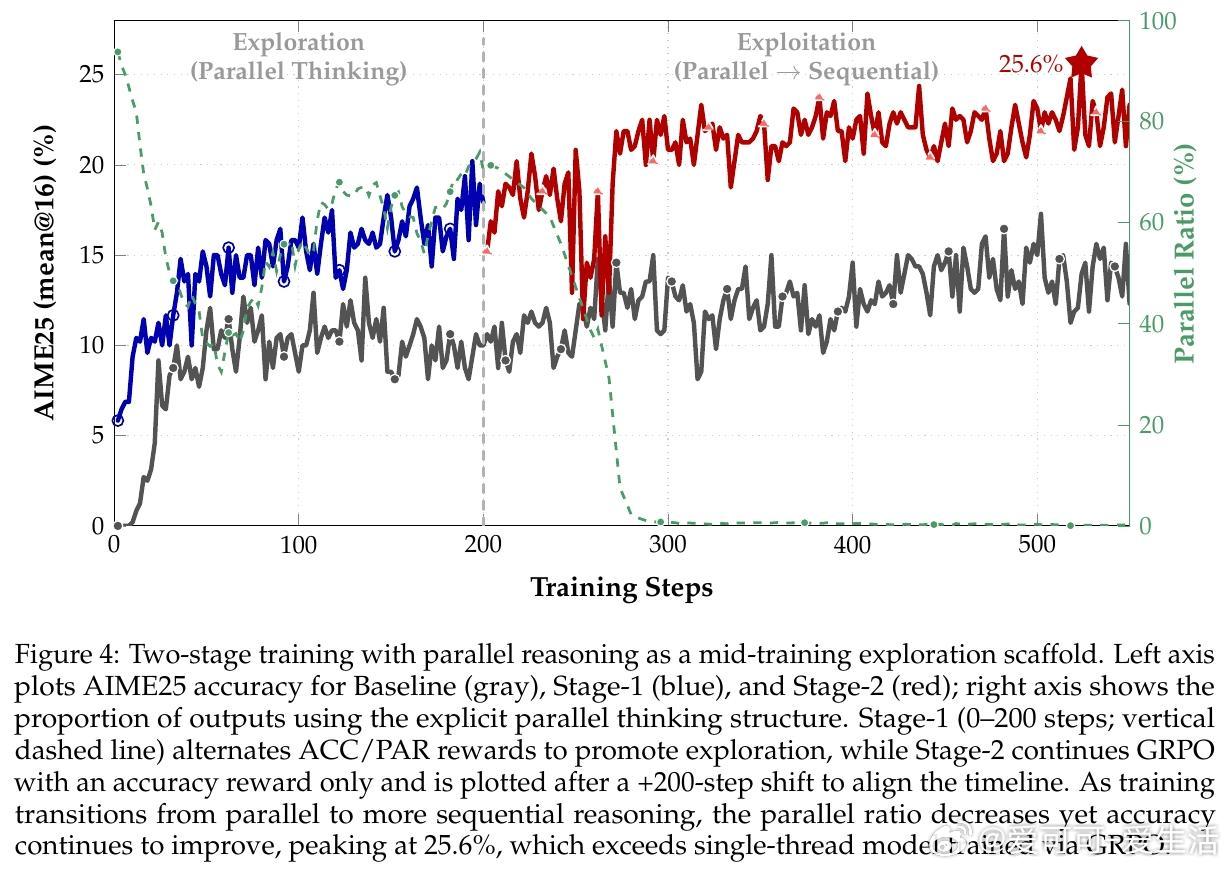
• 实验覆盖AIME、AMC、MATH等多数学基准,最高较传统序贯强化学习模型提升8.4%准确率,AIME25峰值提升达42.9%,验证并行思维作为中期探索策略促进最终性能跃升。
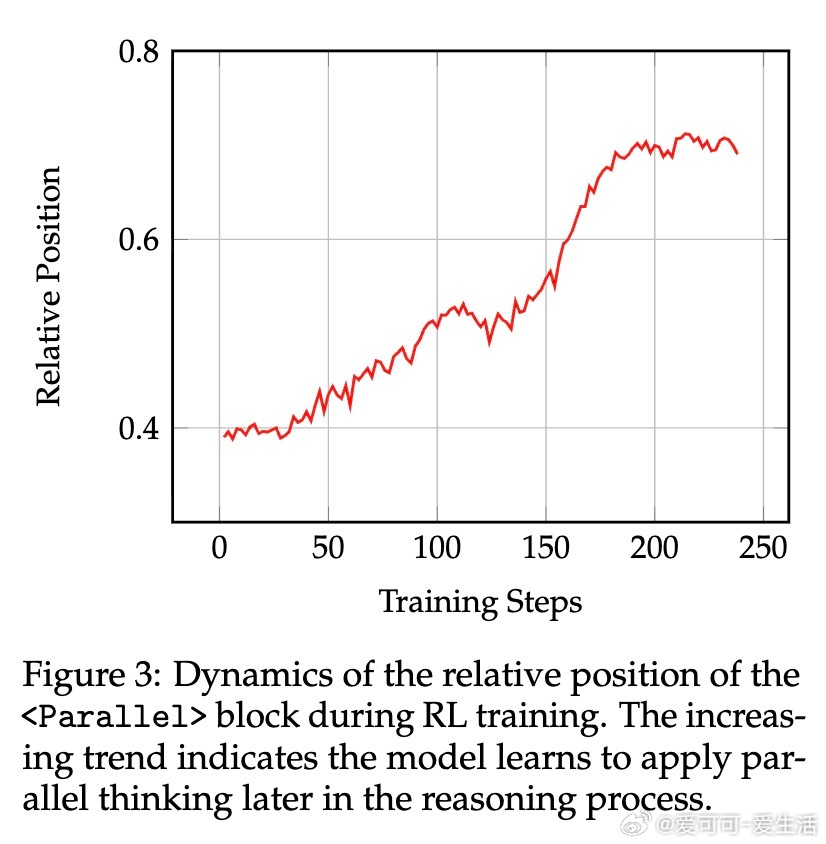
• 训练动态分析揭示模型从初期利用并行思维进行多解探索,到后期转为多视角答案验证,实现风险控制与准确性提升。
• 简洁高效的数据生成管线,利用简单提示生成高质量并行格式示例,解决复杂问题数据稀缺及训练冷启动难题。
心得:
1. 并行思维非简单多线程堆叠,而是动态触发、总结、验证的闭环策略,体现更接近人类认知的结构化推理。
2. 交替奖励机制带来训练稳定性和策略多样性,避免单一目标陷入局部最优,体现强化学习在复杂认知任务中的潜力。
3. 并行思维作为探索脚手架阶段,促进模型跳出局部最优,开启更广阔的策略空间,强调训练过程设计的重要性。
详情🔗 arxiv.org/abs/2509.07980
人工智能大语言模型强化学习数学推理并行思维机器学习