[LG]《Language Self-Play For Data-Free Training》J G Kuba, M Gu, Q Ma, Y Tian... [Meta Superintelligence Labs] (2025)
语言模型训练的瓶颈正在从数据规模转向数据依赖的根本限制。《Language Self-Play For Data-Free Training》提出了一种创新的强化学习框架——语言自弈(LSP),实现了在完全无外部训练数据的条件下持续提升模型性能。
• 核心机制:通过单一模型扮演“挑战者”和“解答者”双角色,挑战者生成逐步升级难度的任务,解答者应对并优化回答,形成零和博弈的自驱动训练循环。
• 自我奖励机制:引入自评估奖励(self-reward)避免模型陷入无意义的对抗性输出,确保训练内容语义合理且富有挑战性,实现了长期稳定的自我提升。
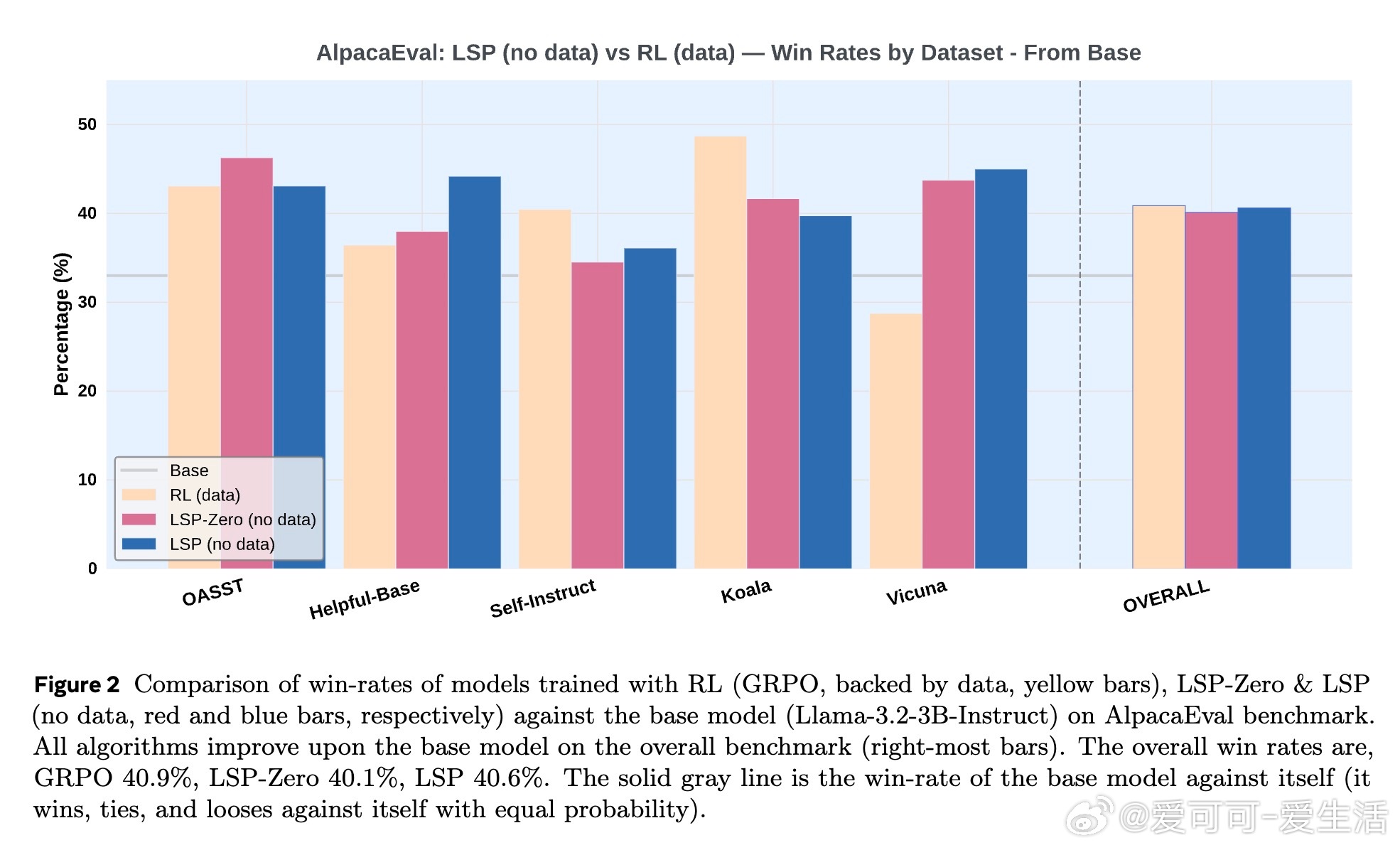
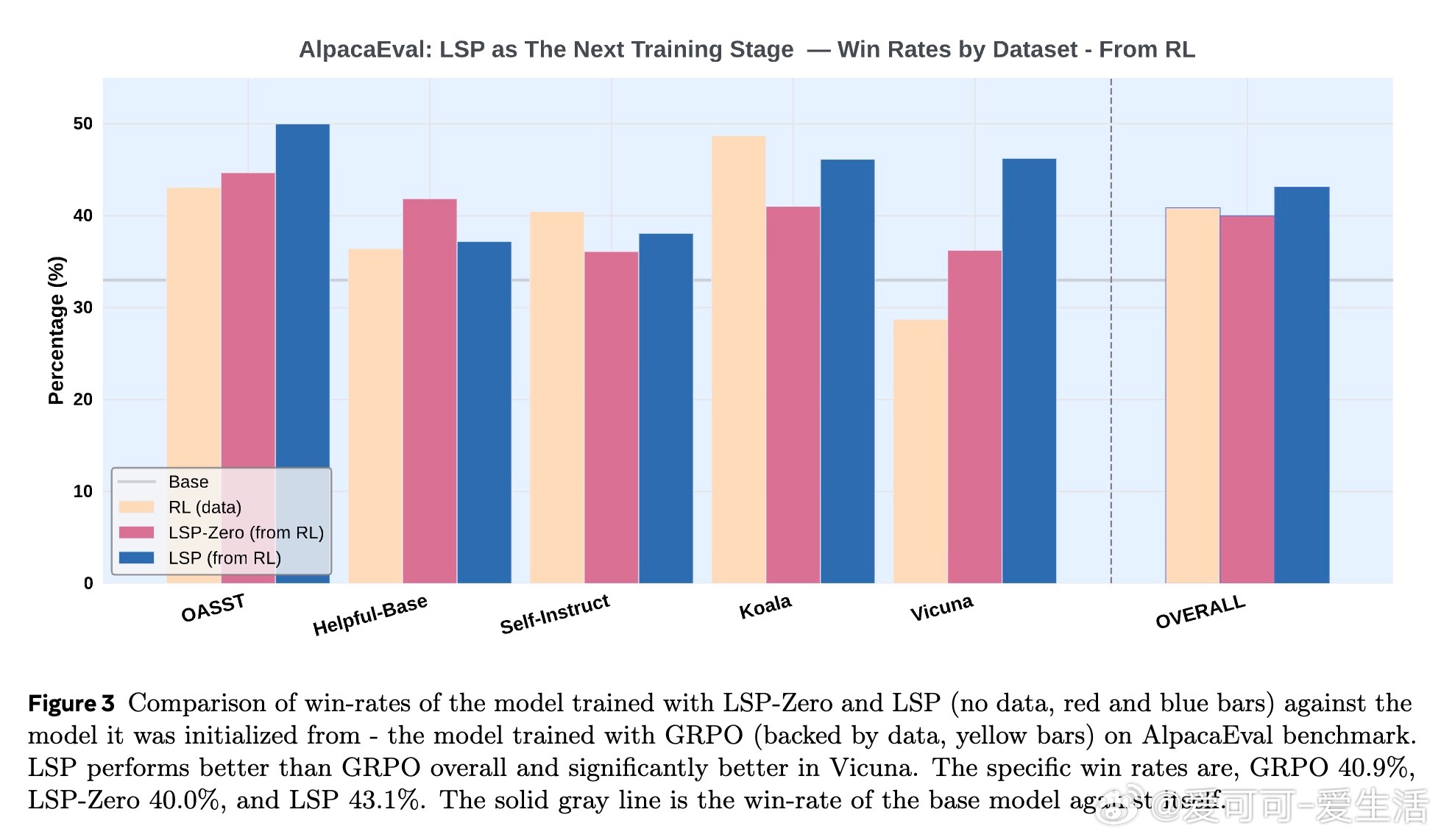
• 实验验证:在Llama-3.2-3B-Instruct和AlpacaEval基准测试中,LSP在无数据条件下达到甚至超越传统基于数据强化学习(GRPO)模型的表现,尤其在对话开放任务(Vicuna)上优势明显。
• 方法优势:无需额外对手模型,避免对抗训练的不稳定性,且动态生成训练样本,突破了传统训练对静态大规模数据集的依赖。
• 持续优化潜力:通过自博弈框架,模型和训练数据集相辅相成,形成正反馈循环,为未来具身智能系统自主采集和利用数据提供理论基础。
心得:
1. 训练数据不再是限制,模型通过自驱动生成挑战,构建“活”数据流,颠覆传统“静态大数据”训练模式。
2. 结合自我奖励机制,有效规避了强化学习中常见的“奖励黑客”问题,保证了训练样本的质量与多样性。
3. 该框架暗示未来AI系统可实现自主学习和进化,迈向更独立、更智能的终极目标。
🔗 arxiv.org/abs/2509.07414
人工智能大语言模型强化学习自博弈无监督训练模型自我提升