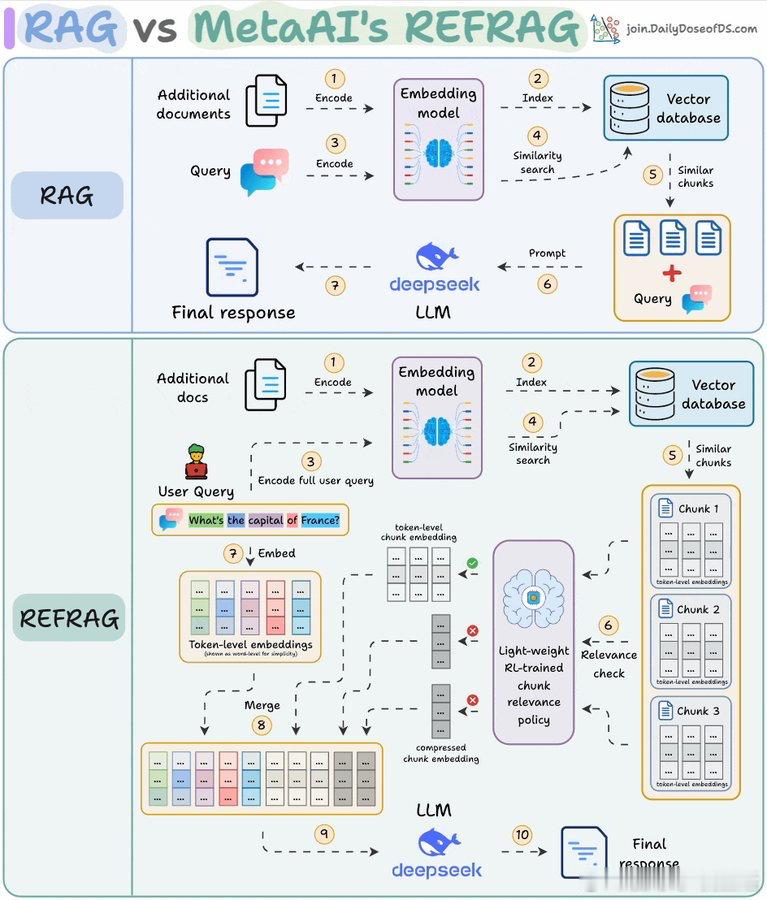
Meta推出REFRAG,彻底解决了RAG(检索增强生成)系统的最大痛点:大量无用信息浪费计算资源。传统RAG会检索上百个文本块,导致模型处理成千上万无关token,成本高且效率低。REFRAG创新地在embedding层面进行压缩和筛选:- 每个文本块先压缩成单个embedding向量- 通过强化学习策略对embedding进行相关性评分- 只展开最相关的文本块送入LLM,其他保持压缩或被过滤- 这样LLM只处理真正重要的信息,显著降低token数量结果惊人:- 首个token响应速度提升30倍以上- 支持16倍更大的上下文窗口- 处理token数量减少2到4倍- 在16个RAG基准测试中超越LLaMA表现工作流程简单高效:1. 编码文档并存入向量数据库2. 查询时检索相关embedding块3. 强化学习策略筛选最优embedding4. 展开选中块为完整token向量5. 其余保持压缩状态6. 所有信息一并输入LLM处理这不仅极大提升了速度和规模,还保证了准确性零损失。REFRAG用“压缩-筛选-展开”的方法,优雅解决了RAG中“token膨胀”的隐藏成本。这一突破彰显了向量空间和强化学习结合在大模型优化中的巨大潜力,也暗示未来检索系统将越来越依赖智能筛选策略,而非盲目堆积信息。它让我们思考:真正的效率,不是无尽扩容,而是精准提炼。论文地址:arxiv.org/abs/2509.01092原推:x.com/akshay_pachaar/status/1989327114303398379