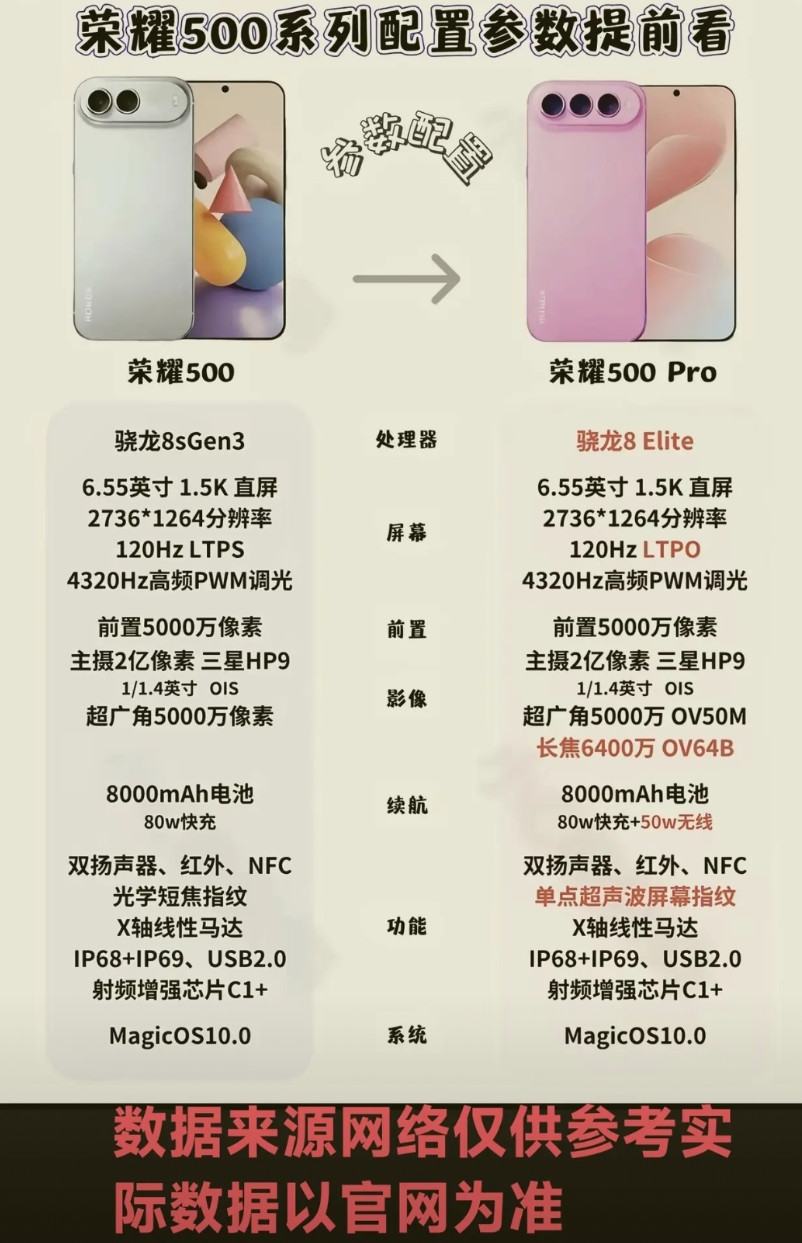
特斯拉 AI5 芯片是如何相比 AI4 提升了 50 倍的?
先说需求,AI5 只有特斯拉这一个客户,需求单一,应用的两个产品线汽车和机器人,都对于能耗、成本极为敏感,对应的指标是每美元性能和每瓦性能。
再说性能,对比目前搭载的 AI4 芯片,AI5 硬化块量化和 softmax 性能提升了 5 倍,内存容量提升了 9 倍,之前 Elon 还提到内存带宽提升了 5 倍,原始算力提升了 10 倍,最后结论是 AI5 整体性能提升了 50 倍。
但特斯拉没有公开过 AI4 的算力,网传在 500 - 720 TOPS 之间,这里 720 TOPS 的出处是特斯拉官方说过 AI4 的算力是 AI3 的 5 倍,即 144*5=720 TOPS。
按照这个数据,AI5 的算力是 7200 TOPS,但实际性能提升不是 10 倍,是 50 倍,这是如何实现的?
答案是软硬件结合带来的算力利用率的进一步提高。比如 AI4 除了 NPU 也有传统的 GPU,这样硬件设计低效,也不利于部署更大的模型。
AI5 删除了 GPU 和 ISP,芯片主要就是内存、NPU、CPU 和 PCI 总线接口,因为只有一个客户特斯拉,AI5 的设计做了极致的定制和简化,算力利用率可以进一步提高。
从特斯拉的角度,AI5 和英伟达 B200 的实际可用性能是基本相当的,但能耗压缩在了 B200 的 1/3,B200 的峰值功率在 1000W,所以 AI5 的峰值功率是 300W 左右。而 AI5 的成本远远不及 B200 的 10%。
再一个是特斯拉在软件方面的整数推理,这又需要从训练到推理的联合优化。
整数运算没有小数,功耗比浮点运算低得多,运算速度飞快,能耗极低,效率极高。在模型推理时全用整数运算,精度损失小于 1%,但速度和能效起飞。
举一个整数计算和浮点计算的例子,假设你要计算 0.00011 × 31415.9265
- 整数量化直接放大 1 万倍,1 × 31416,推理时再除以 1 万还原,结果是精度几乎无损,但效率碾压。
- 浮点计算意味着一点点指数对齐、尾数相乘、舍入,计算更复杂、更慢、能耗更高。
(训练阶段必须用浮点计算,不然会无法收敛,模型必须靠极小的梯度一点点调整权重,如果用整数计算就会被四舍五入成 0,也就是模型学不到东西了。)
Elon 说你的训练流程需要从头到尾针对整数进行优化,这样可以实现浮点训练,训练到中间开始 QAT 量化感知训练,最终实现在车上以 INT8 整数计算部署,精度牺牲小于 1%。
通过以上这些,特斯拉实现了特斯拉 AI5 芯片业内最佳的每美元性能和每瓦性能,相比 AI4 芯片提升 50 倍。
不确定这其中的软硬件工程难度,但似乎也对所有自研辅助驾驶芯片的国产品牌有很大借鉴意义。