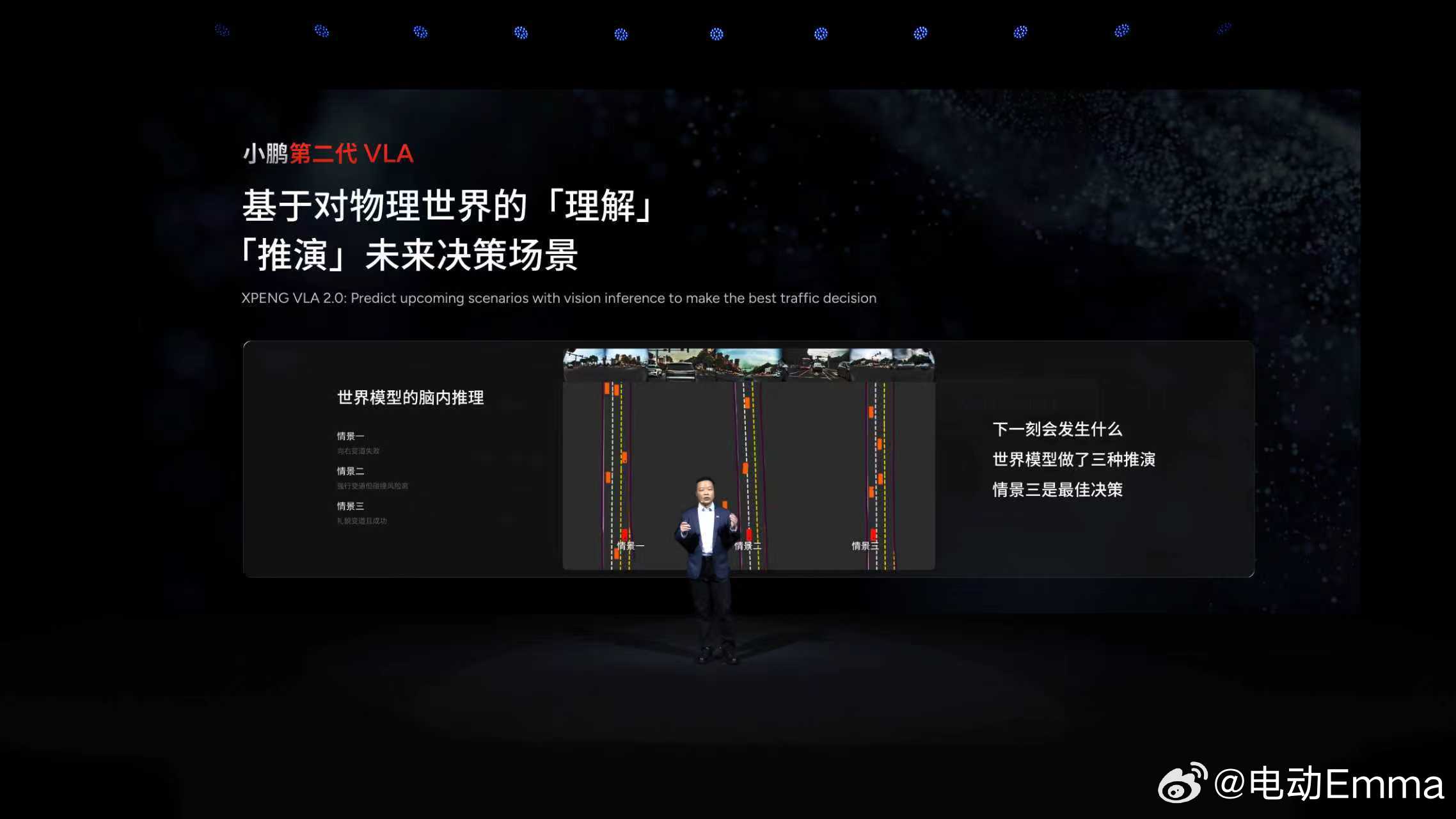
在小鹏AI Day发布会,何小鹏对VLA的理解,跟AI教父杨立坤的一些最新观点不谋而合。
杨立坤:
更高的智能,不能只靠训练文本。
大语言模型大约需要两三万亿个tokens去训练, 一个token通常用3个字节,那也就是训练一个大模型需要1后面跟14个0那么多个字节, 这只是预训练阶段。这是大概互联网所有公开文本的综合,是巨大的信息量。
现在把这个信息量跟我们生命前四年通过视觉系统进入大脑的信息量进行比较时,你会发现这个信息量是差不多的。在4年里,一个小孩醒的时间大概是1.6万小时,通过视觉神经进入大脑的信息量大约是每秒两兆字节,也就是1后面跟14个0那么多byte。
在4年里,一个小孩看到的信息和数据量,与最大的大语言模型相当。也就是说,仅仅通过文本训练,我们永远无法训练出达到人类水平的 AI,我们需要让系统理解现实世界。
何小鹏:
小鹏对VLA大模型理解,不按行业标准 【从Visual(视觉)转换到Language (语言)再到Action (行动)】来规划,而是直接思考“能不能拆掉Language”,去掉语言转译,不以文本而以视觉为核心,追求“百文不如一见”的模型效果。
而这是小鹏在投入 3 万卡算力,烧了 20 多亿的研发费用后,推出的无语言转译方案,期待看看这种 VLA会不会有“质变”。
小鹏科技日何小鹏首次披露物理AI巨大进展