[LG]《Panprediction: Optimal Predictions for Any Downstream Task and Loss》S Balakrishnan, N Haghtalab, D Hsu, B Lee... [CMU & UC Berkeley & Columbia University] (2025)
在多样化需求的机器学习应用中,如何构建一个预测器,使其能适应无限多的损失函数和任务,成为亟待解决的挑战。本文提出了“全局预测(panprediction)”框架,系统性地回答了这一问题。
核心观点如下:
1. 问题背景与动机
在医疗等领域,不同决策者关注不同的损失函数和群体子集,例如ICU医生重视零一损失,精算师看重平方损失,且他们关注的患者子群可能不同。传统方法需针对每个任务和损失单独训练模型,样本需求随着任务和损失数目线性增长,难以扩展。
2. Panprediction定义与优势
Panpredictor是一个单一的概率预测器,能够通过简单的后处理,针对任意损失函数ℓ和群体G,达到竞争最佳假设的效果,误差仅与群体大小的平方根成反比。其样本复杂度仅对群体和假设类的组合维数呈对数增长,且对损失函数类的复杂度依赖极弱,远优于传统逐任务训练。
3. 理论贡献
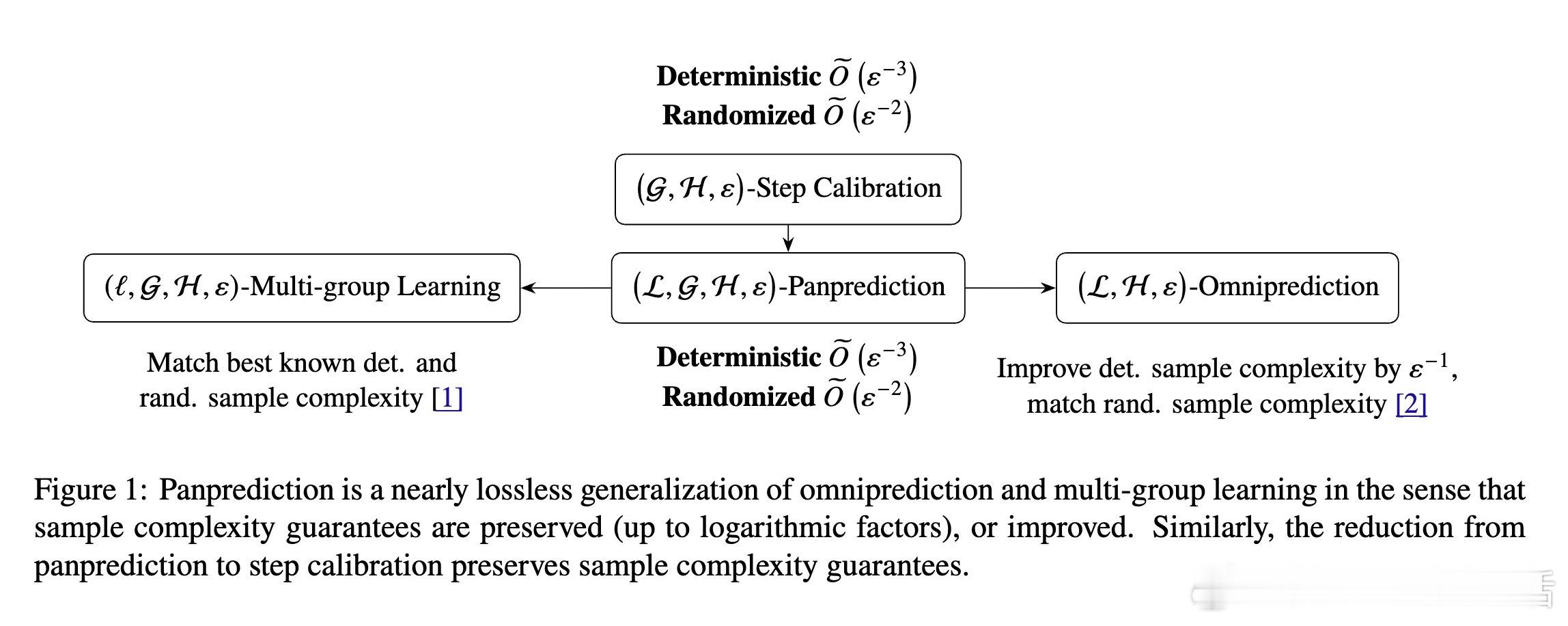
- 引入了panprediction,统一且推广了现有的omnimprediction(适应多损失,单任务)和多群体学习(适应多任务,单损失)两大范式。
- 通过将panprediction问题归约到“阶梯校准(step calibration)”问题,实现了统计复杂度的优化。
- 提出了确定性和随机化的算法,分别实现了𝑂̃(1/ε³)和𝑂̃(1/ε²)的样本复杂度,随机化算法达到单任务单损失的最优下界,表明同时最小化无限多损失和任务在统计上“免费”可得。
4. 关键技术点
- 利用多目标学习框架,设计对抗式no-regret算法和最佳响应查询,解决了高维无限目标优化问题。
- 通过对损失函数的离散导数的逼近,构造了有限维度的阶梯函数基底,使复杂损失函数得以有效近似。
- 采用了自适应数据分析技术,保障算法在有限样本下的泛化和稳定性。
5. 应用和扩展
- Panprediction可直接应用于医疗风险评估、金融风险管理等多损失多群体场景,显著降低数据需求。
- 理论上为设计通用、高效且公平的预测模型奠定基础。
- 未来工作关注统计与计算复杂度间隙、泛化到多类别预测等问题。
总之,panprediction框架为机器学习模型的通用适应性提供了理论保障和实践路径,实现了在多任务多损失环境下的高效预测,极大地推动了机器学习的泛化能力和公平性研究。
原文链接:arxiv.org/abs/2510.27638