全球OCR最强模型仅0.9B百度文心衍生模型刚刚横扫4项SOTA
全球AI多模态竞速激战正酣,百度又放了个大招!
旗下新模型凭借0.9B参数量,在最新OmniDocBench V1.5榜单上拿下92.6分的成绩,获得综合性能全球第一。
它就是百度刚刚发布并在Day 1就开源的自研多模态文档解析模型PaddleOCR-VL。
(ps:0.9B参数量,对开发者的个人电脑真的炒鸡友好!)
发布16小时内,该模型就登顶了抱抱脸Trending全球第一。【图1】
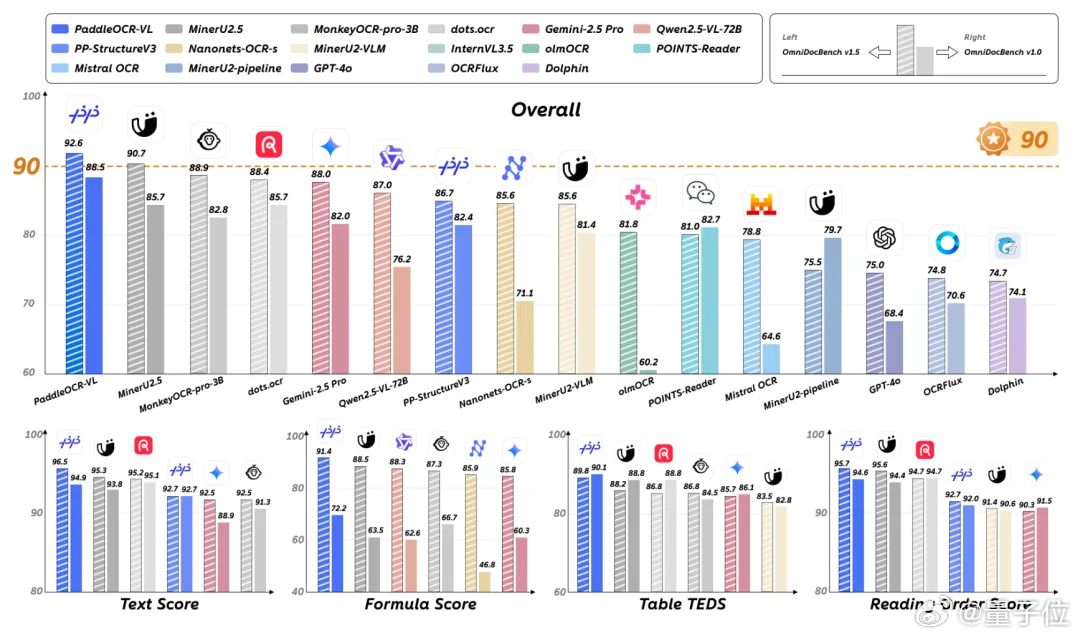
非常抢眼的是,这款模型不仅得分高,它还在文本识别、公式识别、表格理解、阅读顺序四大核心能力上全面拿下SOTA,成为当前唯一在这四个维度全部排名第一的模型,刷新了全球OCR VL模型性能的新高线。【图2】
PaddleOCR-VL是一款面向复杂文档结构解析而设计的模型,是百度文心大模型体系下专注文档解析任务的轻量化衍生产品,具备极强的行业落地导向和平台集成能力,能轻松看懂令人头秃的PDF和图片。
敲黑板划重点:它真的能理解格式杂、长度长的文档中的逻辑结构、表格关系、数学表达等等。
𝕏和小红书等平台上,这个模型已经被大家先用起来并分享使用体验。实用又好用,已经收获“哇”声一片。【图3】【图4】
在AI从感知到认知不断跃迁的当下,当模型不再只是识字工具,变成了具备结构感知与语义还原能力的利器,OCR在AI时代的意义也被彻底改写。