[RO]《Learning to Grasp Anything by Playing with Random Toys》D Niu, Y Sharma, B Shi, R Ding... [UC Berkeley] (2025)
提出一种创新机器人抓取学习方法,显著提升了对新颖物体的泛化能力。
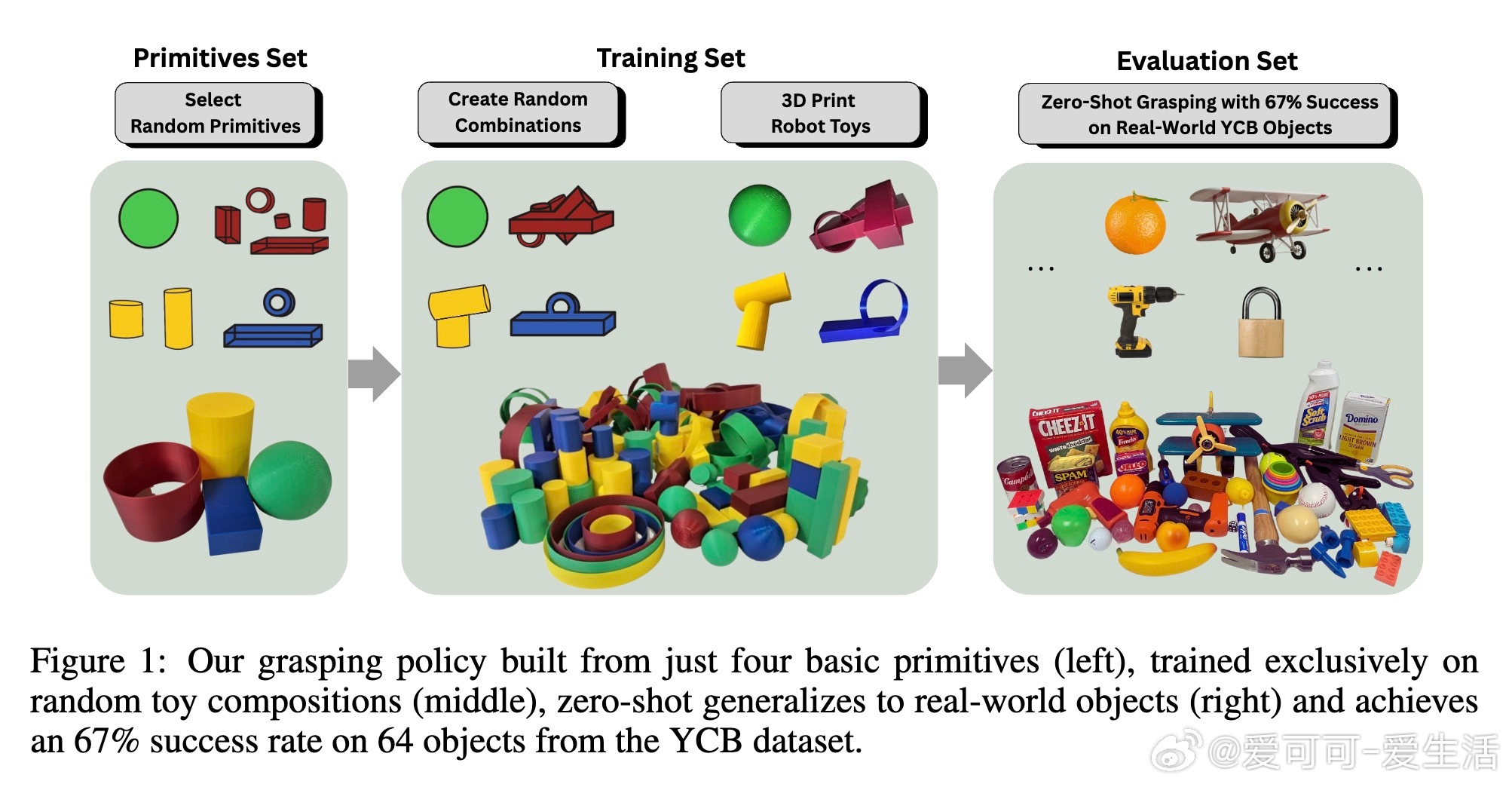
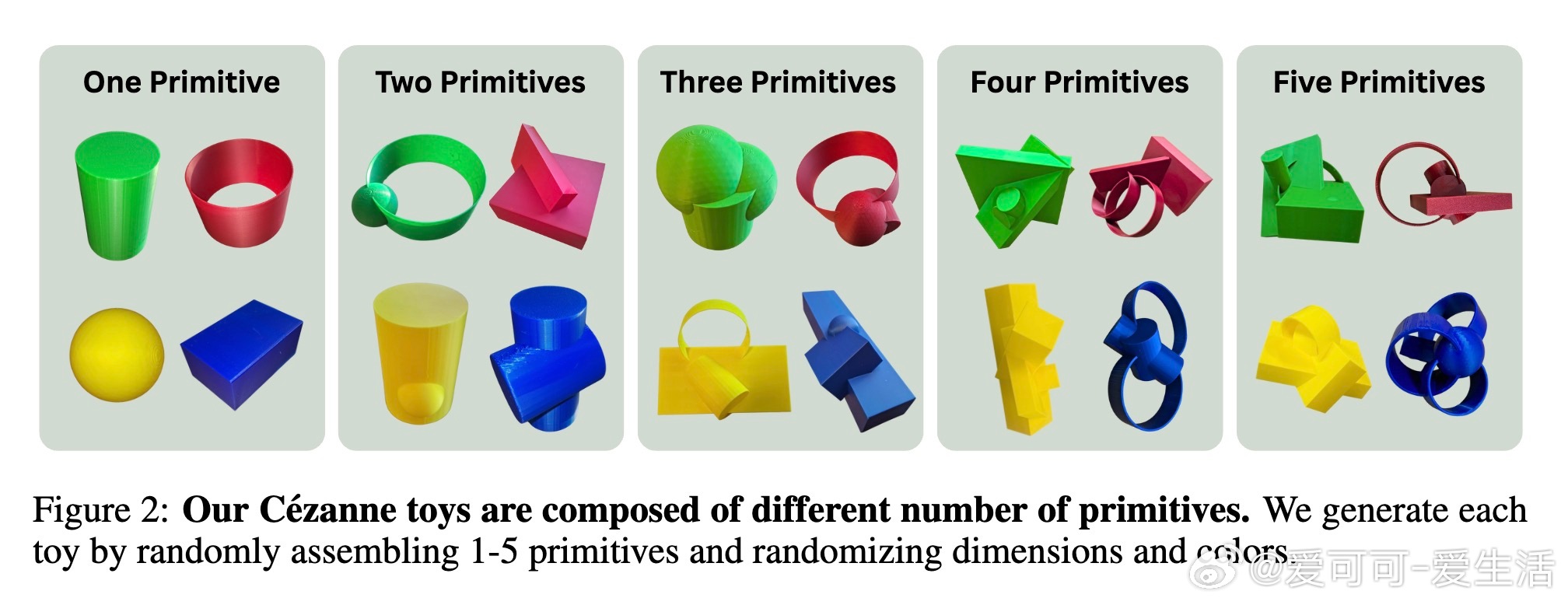
核心思想源自认知科学:儿童通过掌握少量简单玩具的操作,发展出泛化的灵巧操作技能。受此启发,研究团队设计了由四种基本形状(球体、长方体、圆柱体和环形)随机组合而成的“塞尚玩具”(Cézanne toys),用于训练机器人抓取策略。
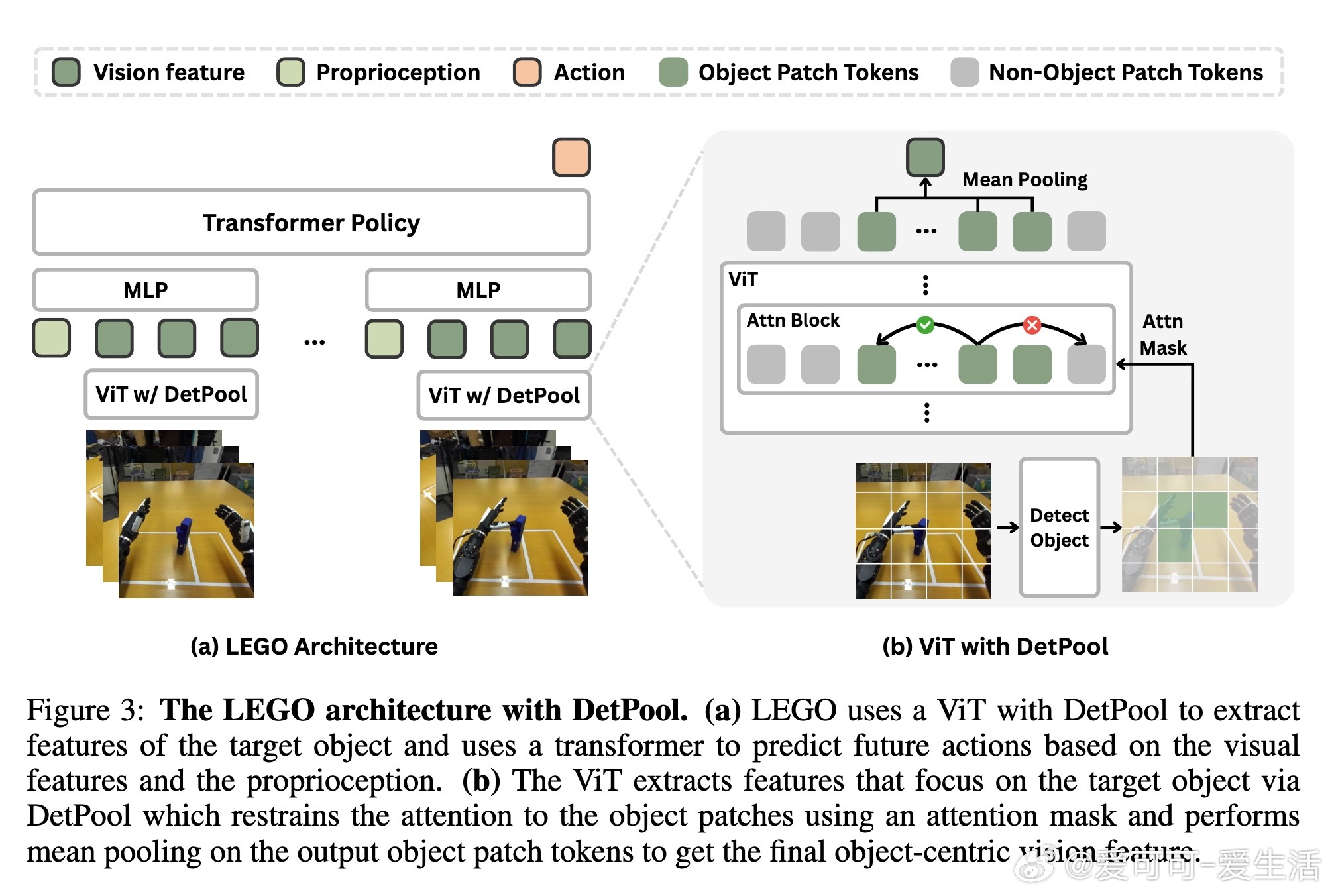
关键创新是引入“检测池化”(Detection Pooling,DetPool)机制,通过目标物体的分割掩码引导视觉编码器聚焦物体区域,剔除背景干扰,生成面向对象的视觉表征。这种表征极大提升了模型在训练与测试对象差异巨大的情况下的零样本泛化能力。
实验证明,该方法在模拟环境和真实机器人(Franka机械臂及H1-2类人型机器人)上均表现优异:
- 在YCB真实物体数据集上,模型实现了67%的抓取成功率,超越了依赖大规模领域内数据预训练的OpenVLA-OFT和π0-FAST等先进模型。
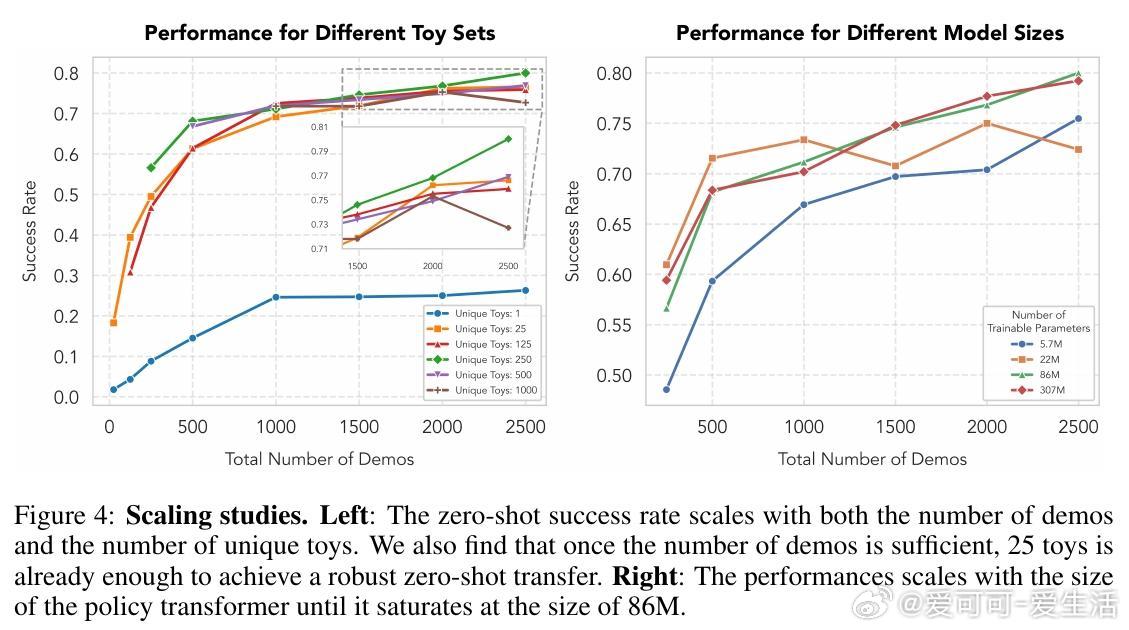
- 研究还系统分析了训练玩具的数量、多样性及演示次数对泛化性能的影响,发现演示次数对性能提升尤为关键。
- LEGO方法对不同机器人硬件结构均展现鲁棒的适应能力,从简单夹爪到复杂灵巧手均有良好表现。
该工作为机器人操作的可扩展泛化学习开辟了新路径,表明从少量基础形状构成的随机组合物体中学习,配合面向对象的视觉表征,足以实现对复杂真实物体的有效抓取。
项目官网提供了详细数据集、代码及演示视频,便于社区复现与拓展:
lego-grasp.github.io
全文及详细技术细节请见:
arxiv.org/abs/2510.12866
这项研究不仅验证了认知科学启发的有效性,也为未来机器人在多样化未知环境中的自主操作奠定了坚实基础。期待后续拓展至更复杂操作任务和资源受限设备的优化方案。