[RO]《VLA-0: Building State-of-the-Art VLAs with Zero Modification》A Goyal, H Hadfield, X Yang, V Blukis... [NVIDIA] (2025)
VLA-0:零改动即可打造顶尖视觉-语言-动作模型
提出了一种极简但极为有效的视觉-语言-动作模型(VLA)设计思路:
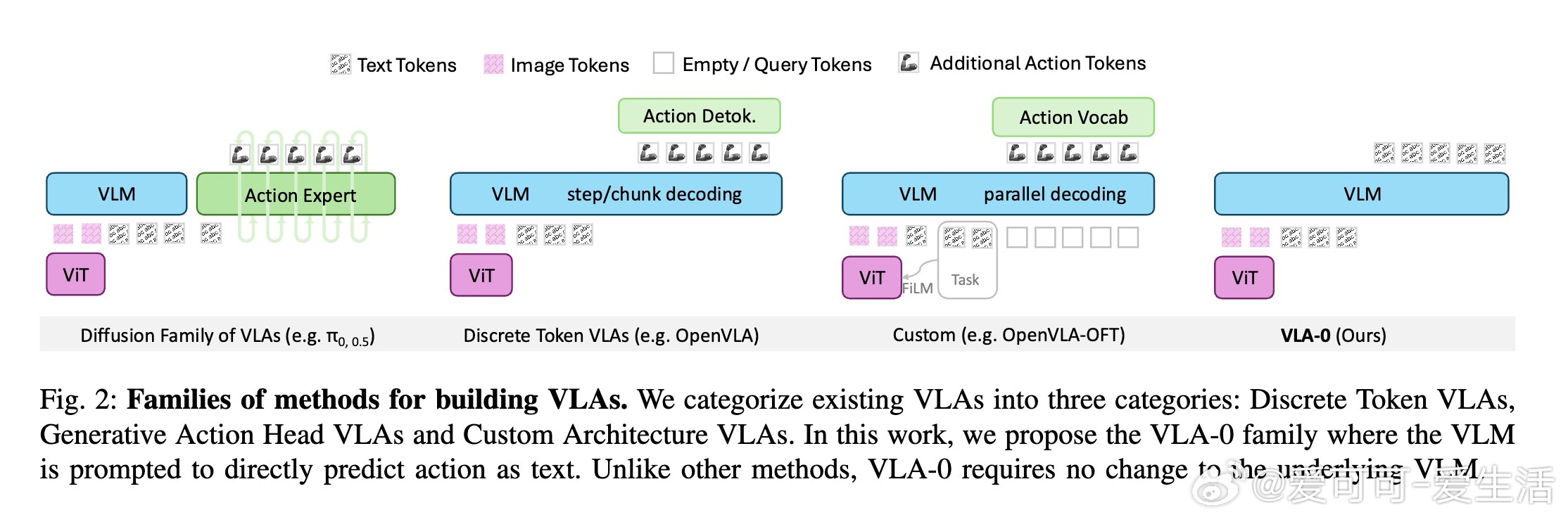
1. 背景:当前VLA主要有三类构建方式:
- 离散动作Token:将连续动作离散化为词汇表中的Token,但分辨率有限且影响语言理解;
- 生成式动作头:在VLM上加动作生成模块,提升动作质量但增加复杂度且可能损害VLM原能力;
- 定制架构:引入专用动作头或自定义Token,效果好但训练复杂。
2. 核心创新:VLA-0直接将动作(如坐标、关节角度)用字符串数字形式表示,利用VLM原生文本生成功能,无需改动词汇表、架构或引入新模块,实现动作预测。该方法简单却强大,避免了复杂设计带来的弊端。
3. 关键技术:
- 动作解码:将连续动作归一化为固定整数区间,VLM输出空格分割的数字序列;
- 预测集成:对同一时间步的多次预测取平均,稳定决策;
- 动作掩码增强:训练时随机遮蔽部分动作数字,迫使模型依赖视觉和语义信息而非简单自动补全。
4. 实验结果:
- 在广泛使用的机器人操作基准LIBERO上,VLA-0在无大规模动作预训练条件下,超越所有同类未预训练模型,并击败多款经过大规模动作预训练的先进模型;
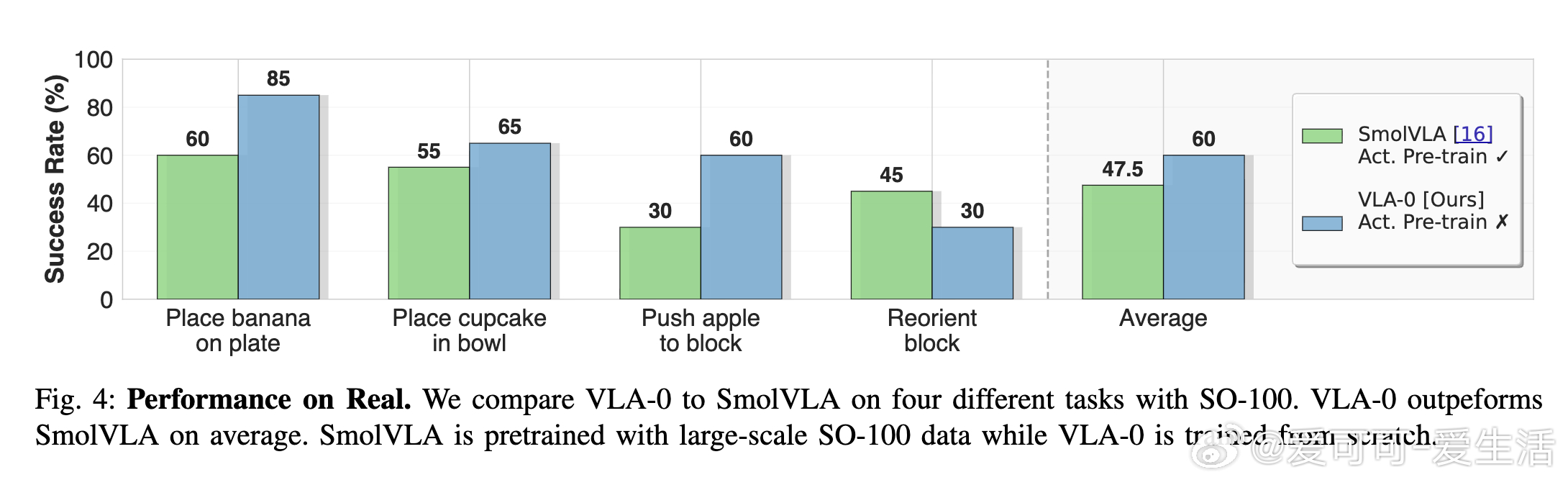
- 在真实机器人平台SO-100上,VLA-0击败了预训练的SmolVLA,验证了其现实适用性;
- 消融实验显示,动作集成和掩码增强显著提升性能,动作分辨率调节也影响表现。
5. 优势总结:
- 设计极简:无需修改底层VLM,保持其语言视觉理解能力完整;
- 性能卓越:超越多种复杂或预训练模型,性能稳定且鲁棒;
- 实用性强:适用多种视觉输入格式,推理速度可接受,未来可通过蒸馏量化进一步加速。
6. 未来展望:
- 探索结合大规模动作预训练,进一步提升表现;
- 优化推理效率,支持更高频率实时控制;
- 研究更复杂任务中的泛化能力。
该工作颠覆了“动作必须特殊处理”的传统观点,展示了“动作即文本”的极简而强大的潜力,为机器人操作AI设计提供了全新思路。
详细论文:
机器人 视觉语言模型 机器学习 VLA 机器人操作 人工智能
链接:arxiv.org/pdf/2510.13054