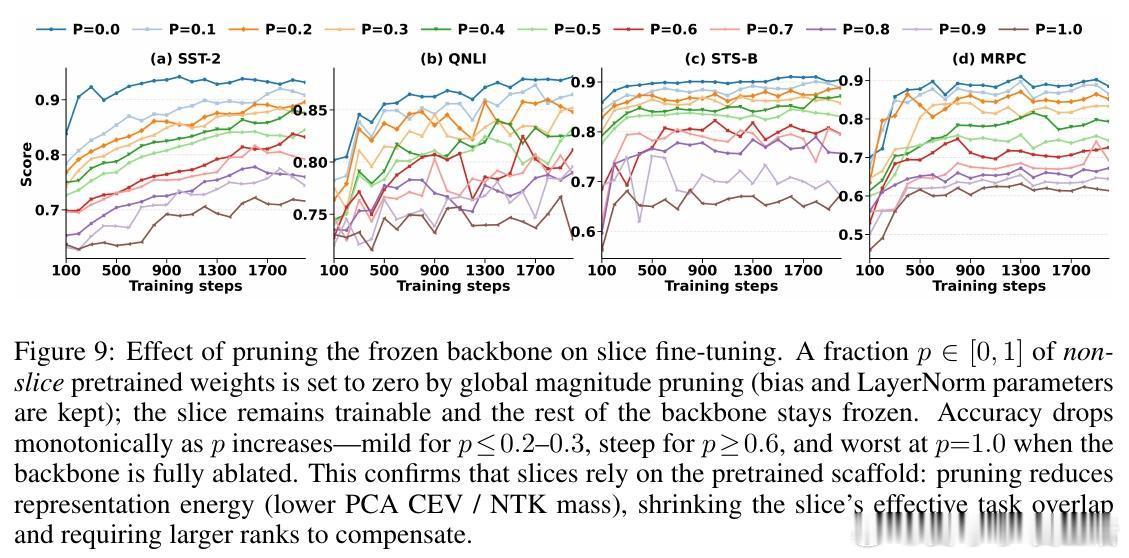
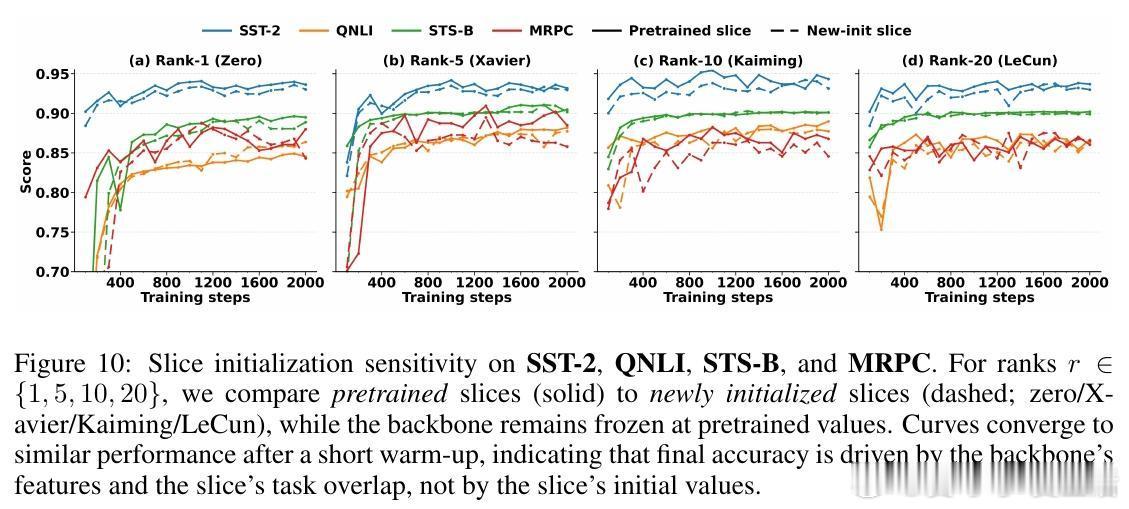
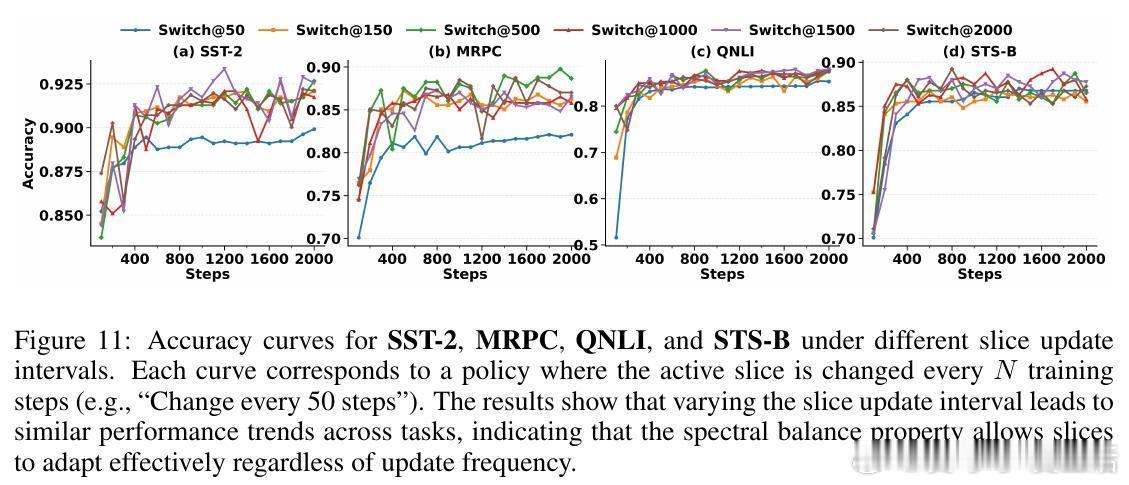
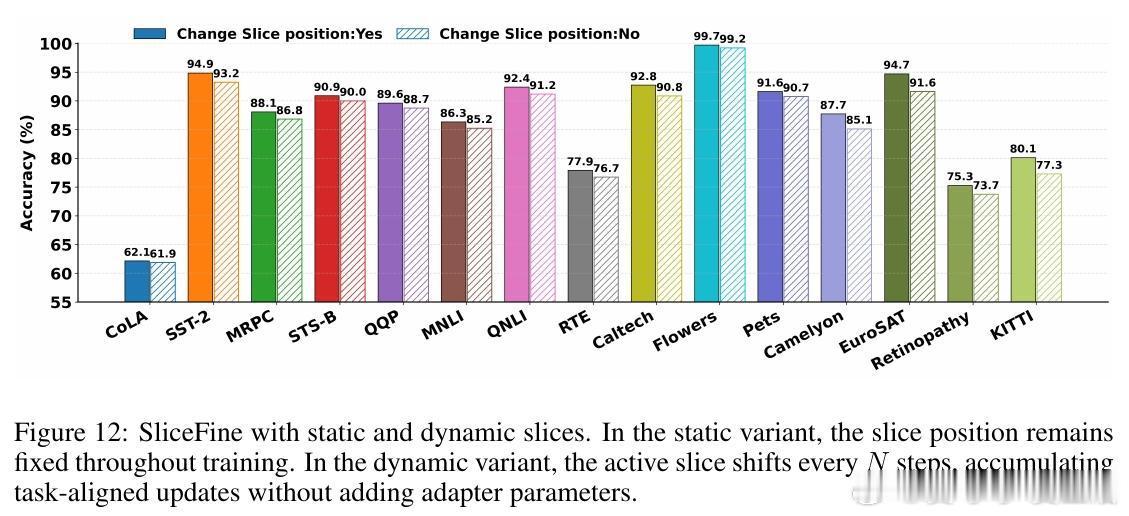
[LG]《SliceFine: The Universal Winning-Slice Hypothesis for Pretrained Networks》M Kowsher, A O. Polat, E M Ardehaly, M Salehi... [Meta] (2025)
SliceFine:预训练网络泛用“赢家切片”假说与高效微调方法
🔍 论文提出“Universal Winning Slice Hypothesis (UWSH)”:
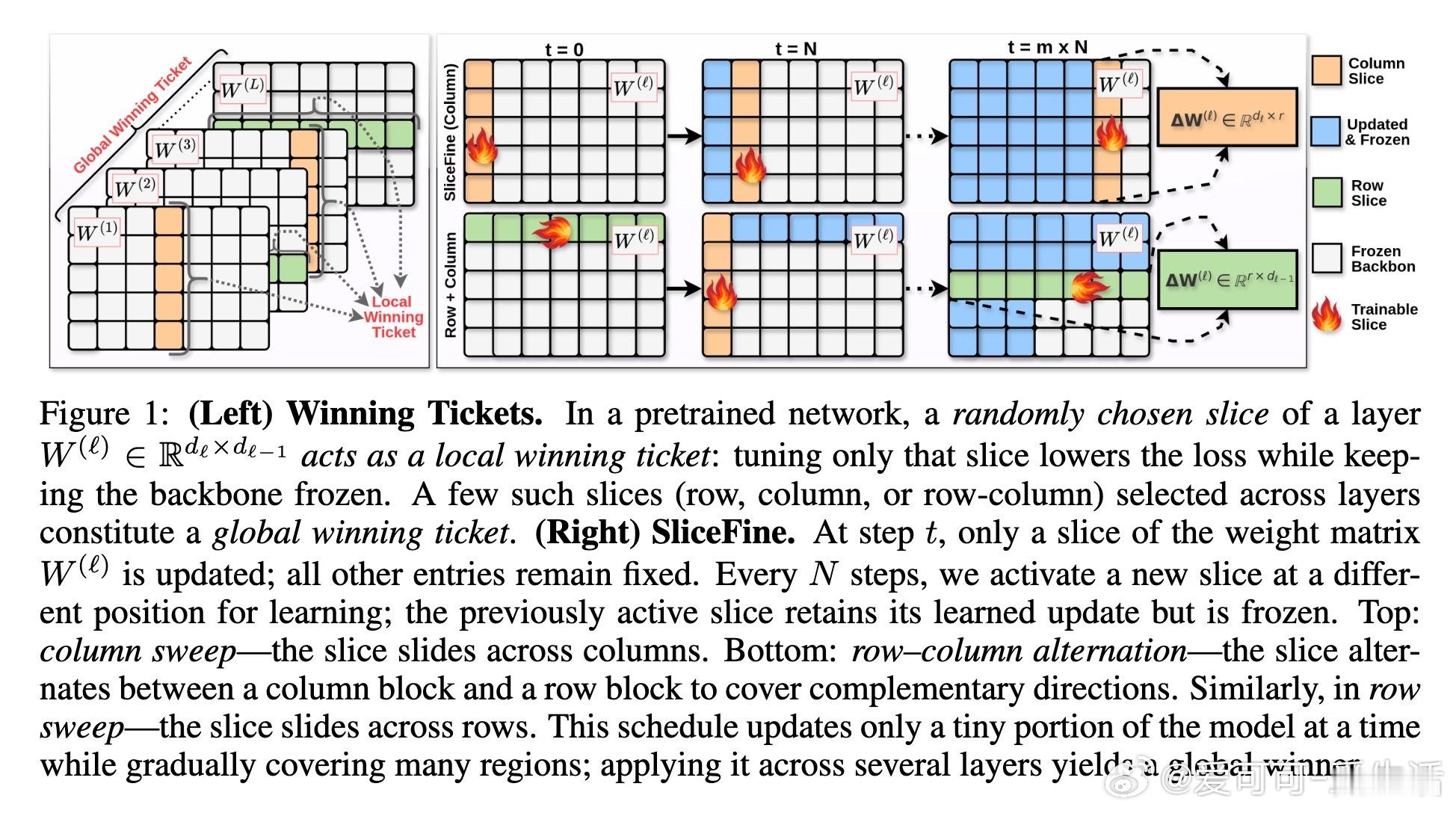
在预训练大模型中,任何足够宽度的随机权重切片(slice)都能作为局部“赢家切片”,单独微调即可提升下游任务表现;多个此类切片跨层联合微调则能媲美全模型微调 —— 无需新增参数!
🎯 关键理论支撑:
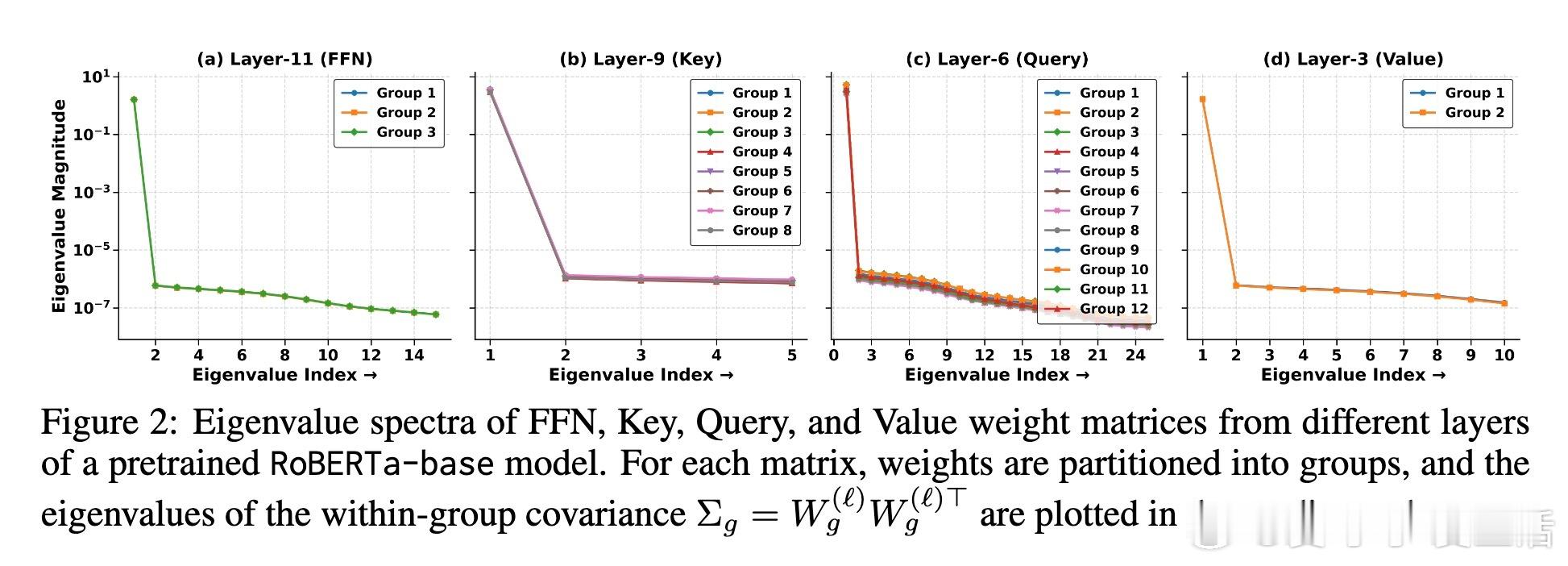
1️⃣ 谱平衡(Spectral Balance):同一层权重矩阵不同切片的特征谱高度相似,能力均衡。
2️⃣ 高任务能量(High Task Energy):预训练骨干网络已具备丰富的任务相关特征,切片必然与这些重要方向有重叠。
🛠 基于此,作者设计SliceFine:
- 仅微调权重矩阵中的小切片,逐步覆盖多位置,动态冻结已训练切片;
- 无需引入额外参数,极大节约内存与计算;
- 训练速度快,模型更轻量。
📊 实验实证:
- 跨语言理解、常识推理、数学推理、图像与视频任务均表现优异;
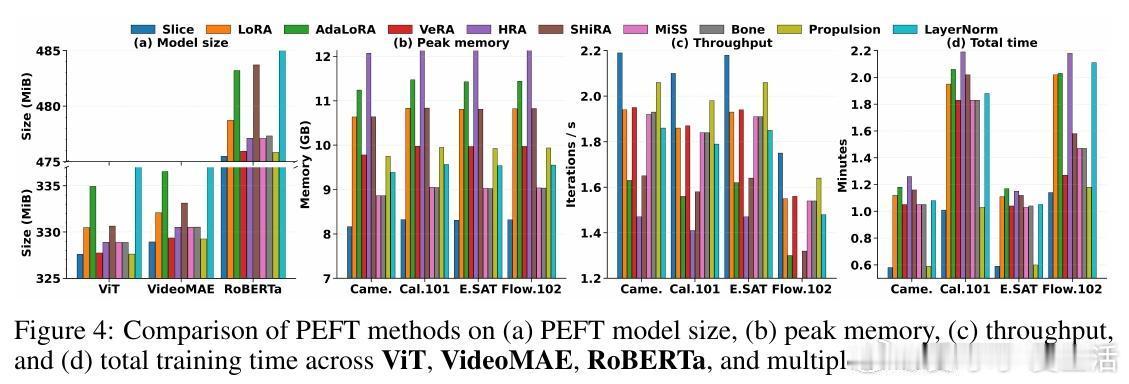
- 性能匹配或超越当前SOTA PEFT方法(如LoRA、AdaLoRA等);
- 训练内存降低18%,速度提升15-25%,整体训练时间减少40%以上。
💡 深度洞察:
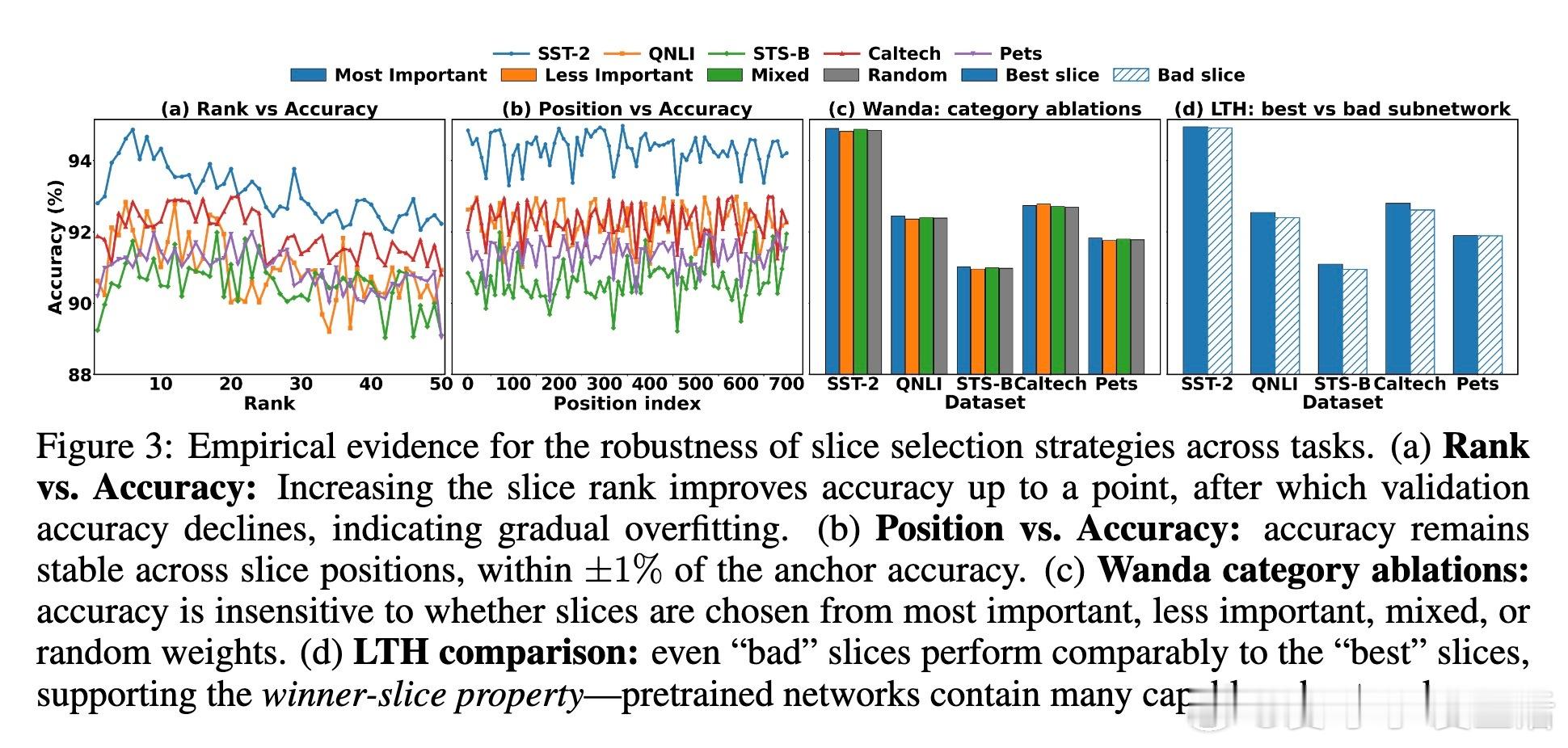
- 切片宽度(ranks)可由任务特征的PCA谱确定,任务相关特征越集中,所需切片越小;
- 预训练骨干的质量直接影响切片微调效果,骨干弱则需更大切片或更多切片联合;
- 切片位置选择对性能影响微乎其微,支持随机或循环更新策略。
🌐 论文链接:arxiv.org/abs/2510.08513
📢 总结:
SliceFine为大规模预训练模型微调提供了理论与实践的统一视角,证明了“任何切片皆赢家”的普适性,开启了无需新增参数的高效微调新篇章!适合在资源受限环境快速适配下游任务。
机器学习 深度学习 预训练模型 参数高效微调 SliceFine AIResearch