[LG]《Agent Learning via Early Experience》K Zhang, X Chen, B Liu, T Xue... [Meta Superintelligence Labs & The Ohio State University & FAIR at Meta] (2025)
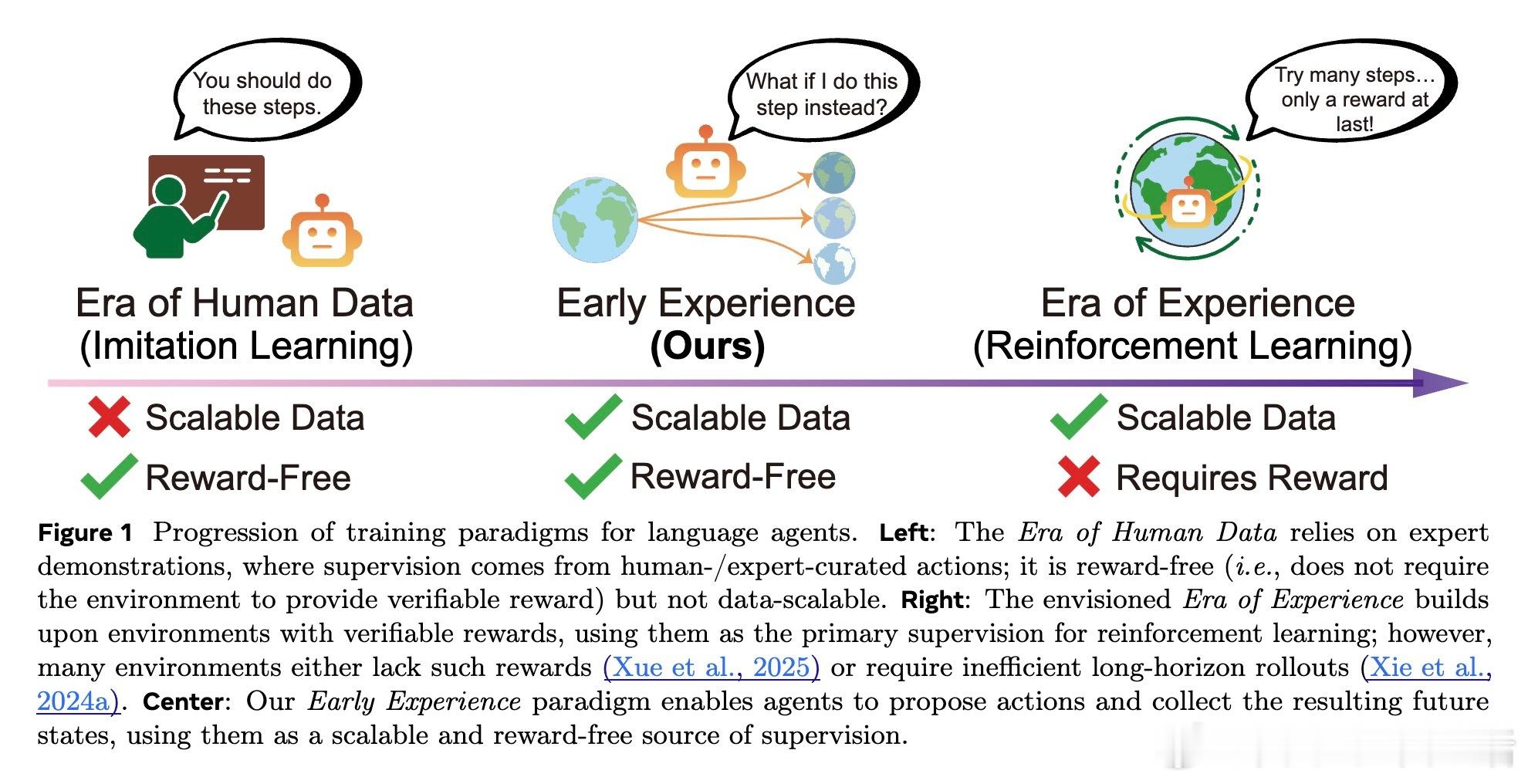
Meta与俄亥俄州立大学联合发布《Agent Learning via Early Experience》新研究,提出“早期经验”范式,助力语言智能体从自身交互中学习,无需依赖环境奖励信号。
🔍背景:
当前语言代理大多基于专家示范监督学习,数据稀缺且泛化差,强化学习受限于环境奖励难以设计或稀疏,导致训练效率低下。
🎯贡献:
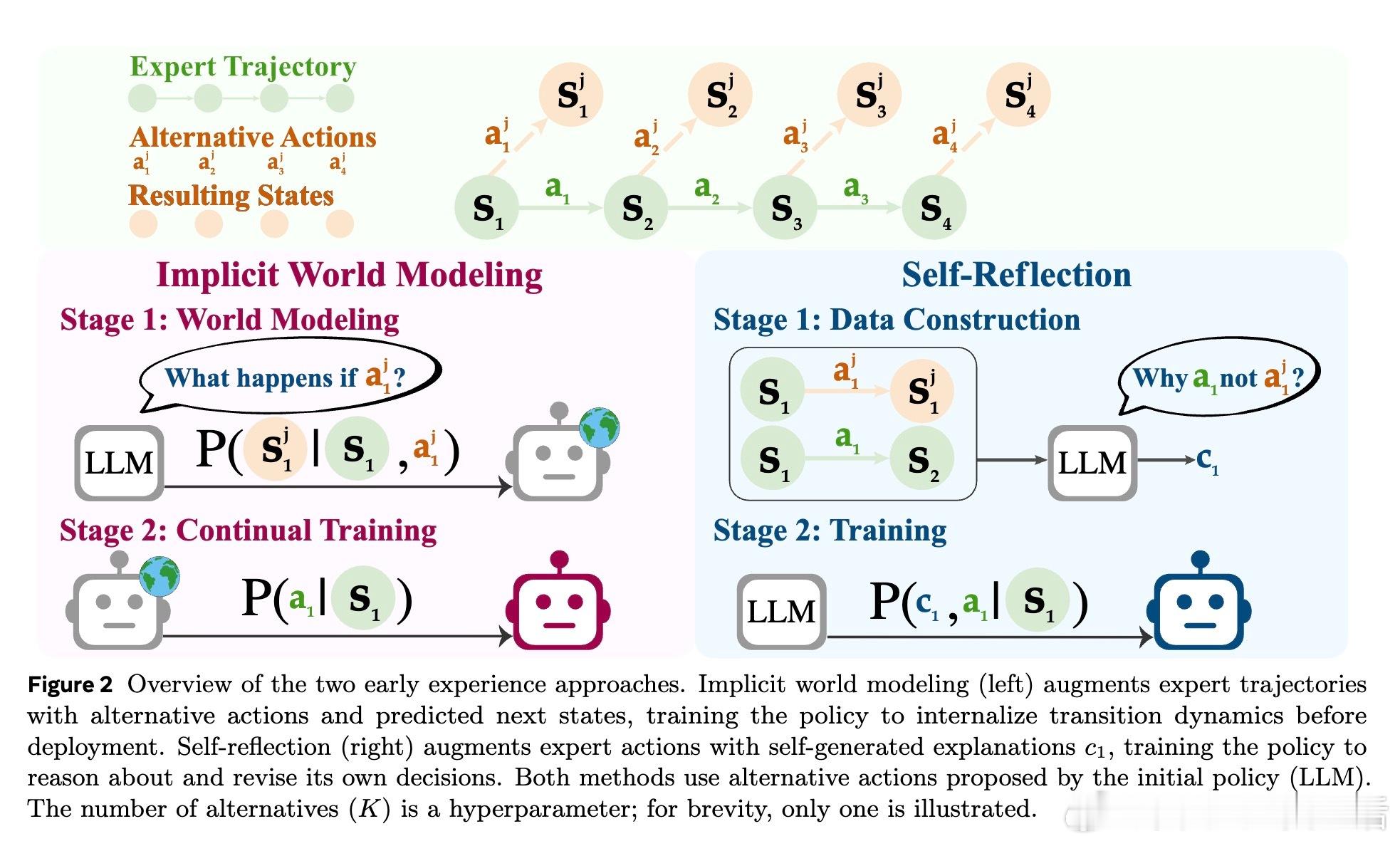
1️⃣ 早期经验范式:智能体主动执行多样化操作,收集由自身行为产生的未来状态作为无奖励的监督信号,实现从自身“经验”中学习。
2️⃣ 两大策略:
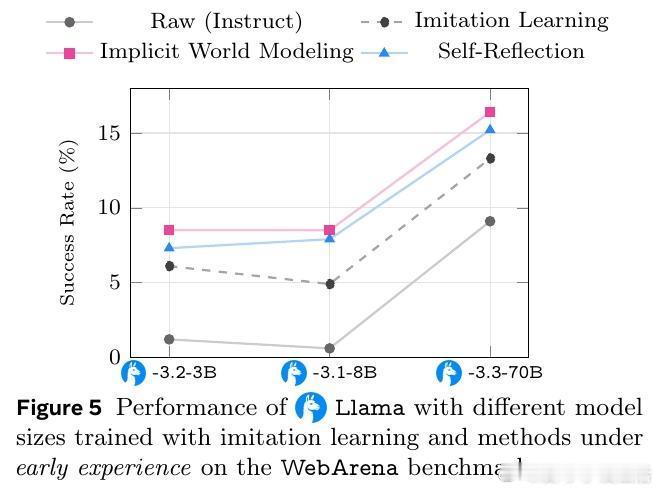
- 隐式世界建模(Implicit World Modeling):基于未来状态预测,内化环境动态,增强策略决策能力。
- 自我反思(Self-Reflection):对比专家动作与自拟动作结果,生成自然语言推理,提升对错误行为的理解与改进。
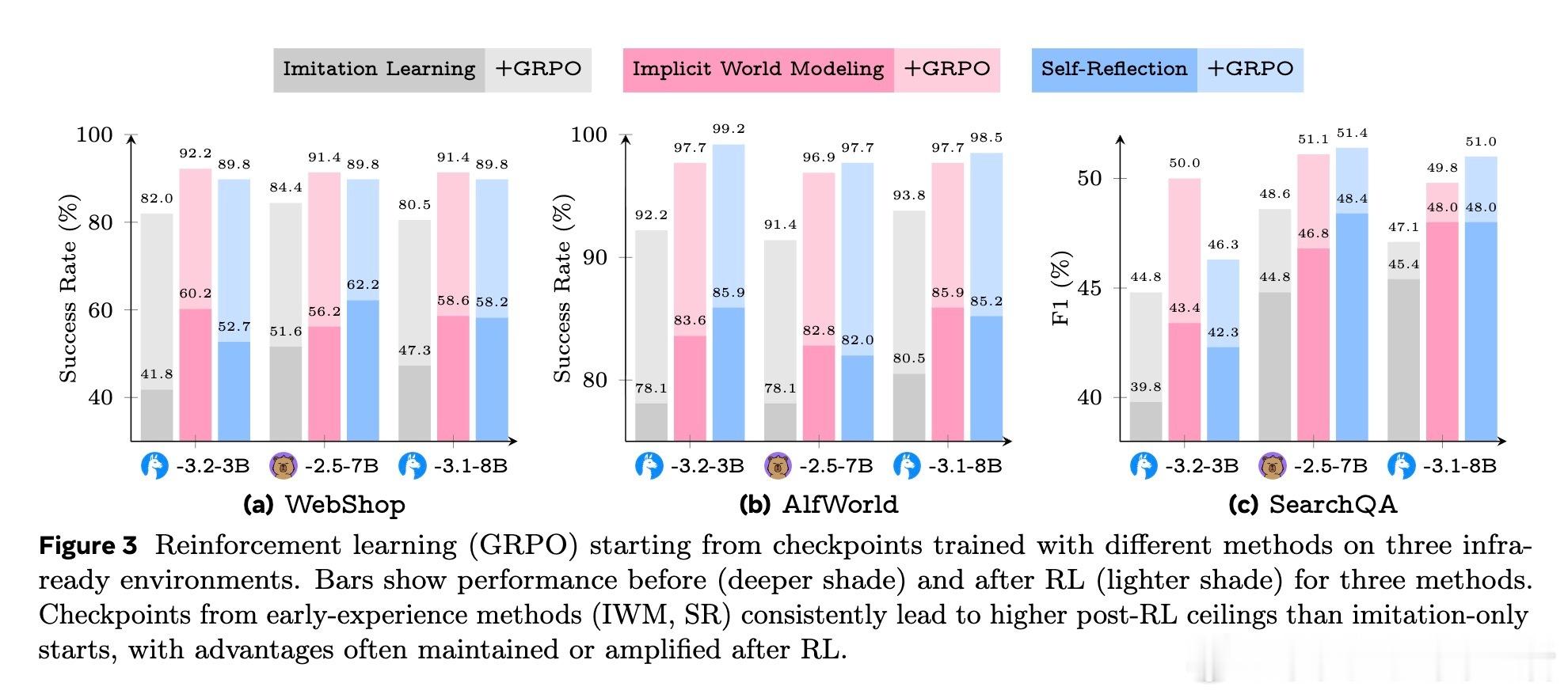
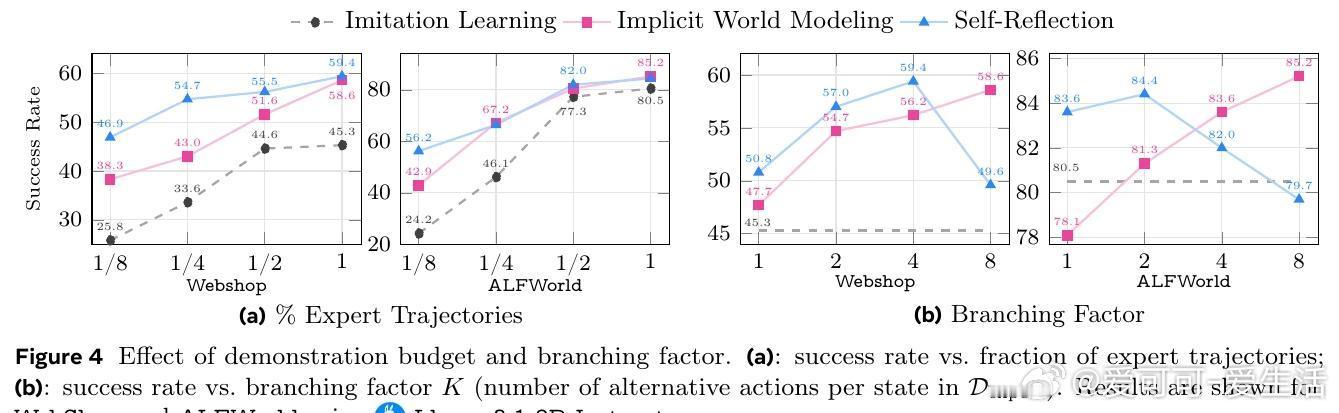
3️⃣ 多环境多模型实证:涵盖8种不同任务(网页导航、多轮工具调用、科学实验、长程规划等),显著提升成功率+9.6%,强化泛化能力,且为后续强化学习提供强劲预训练基础。
🚀亮点:
- 早期经验无需外部奖励,极大拓展了可训练环境范围。
- 训练过程高效,能用更少专家数据达到更优性能。
- 方法对模型大小和环境复杂度均表现稳健。
- 作为监督学习与强化学习的桥梁,推动语言智能体迈向真正自主学习时代。
🤖未来方向:
拓展长程信用分配、结合多任务迁移、实地大规模部署,持续推动语言代理的自我成长与智能化。
详细阅读👉 arxiv.org/abs/2510.08558
人工智能 机器学习 语言模型 自主学习 早期经验