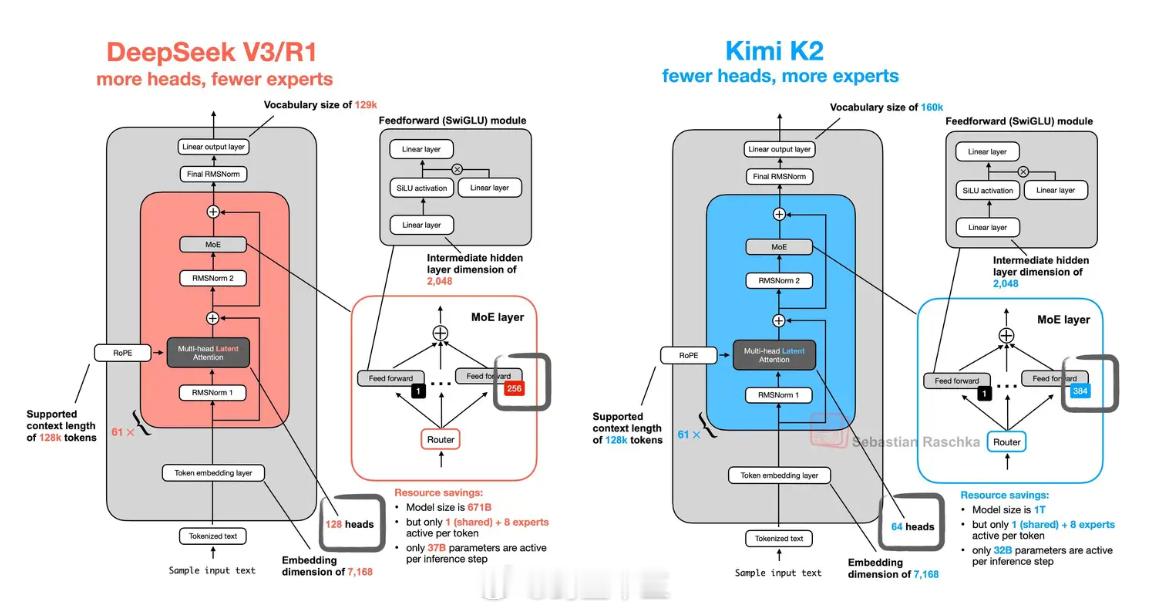
简短聊聊 Kimi真正火在哪里? 第一眼看Kimi其实不会觉得是技术上的大幅突破,更多是在原DS架构上的工程化改善,砍了head_n加了expert_num这种操作更类似“面多加水水多加面”,最后调整出一个性能更好的版本,万亿参数不是核心重点。 在翻了一晚上推特之后,个人认为Kimi在外网的爆火主要来自三点原因: 1) 开源而且便宜(相对Claude)而且编程能力强:便宜的生产力工具总是容易出圈的; 2)极强的工具调用能力:从grok 4到kimi再到今晚放出来的Chatgpt Agent,一个共同的趋势是在训练中大量合成API Call 案例代码,通过在模型训练时大量加入以代码定义的工具调用行为,来实际增强模型的工具调用能力。过往Agent训练的困扰往往在于如何制作Agent行为数据,但通过把行为任务拆分成工具调用、环境反馈、错误重试、输出内容的代码,确实能得到极高的工具调用成功率; 3)从 chat-first 变成 artifact-first:简单来说从输出文本转变成输出“代码构成的页面”,这种范式下也方便用户做进一步的追问、修改、迭代,核心是提升用户的体验感。 总结一下来说,从Kimi再到今晚流出的Chatgpt Agent,本质上是在编程能力过线的基础上,重点通过对工具使用、输出界面的优化(都是以编程为基础),从而实现用户体验的大幅提升,个人认为这是Kimi火爆出圈的核心原因。 后续基于编程能力+浏览器工具交互+前端界面编程输出的范式,大概率会成为一种常态,核心在于代码行为数据丰富且容易定义,期待这种范式继续演进后,用户体验能提升到何种地步。