几个德国同学发现,近期多篇声称通过强化学习(RL)提升语言模型推理能力的论文存在基线评估错误,导致其宣称的RL效果被夸大甚至无效,特别是一些网红论文 [允悲]
看了下包括俺前几天发的这篇: 和这篇
全文在notion上:
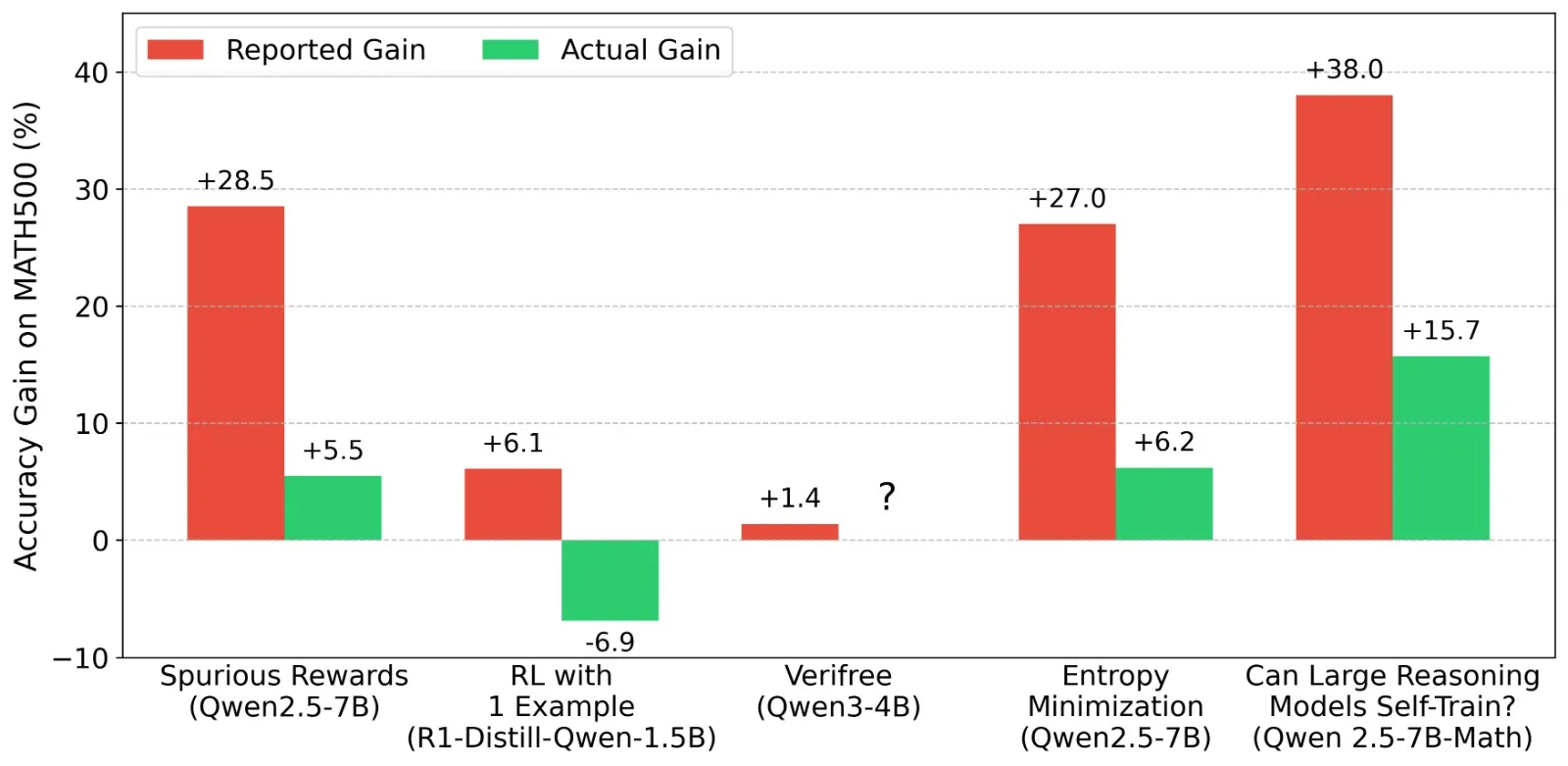
“近期涌现出大量论文,提出了新的强化学习(RL)方法,并声称能够提升语言模型的“推理能力”。其中,最新的几篇论文表明,即使在随机奖励或没有外部奖励的情况下也能实现改进,这引起了广泛的关注和兴奋。
我们分析了7篇热门的大型语言模型(LLM)强化学习论文(在X社交平台上的点赞数从100+到3000+不等,浏览量从5万+到50万+不等),其中包括《Spurious Rewards》、《RL from 1 example》以及3篇探讨“内在置信度奖励”的论文。我们发现,在这些论文中的大多数情况下,不同强化学习方法带来的改进实际上并不明确。这是因为,与Qwen官方发布的数据或其他标准化评估(例如Sober Reasoning论文中的数据)相比,这些论文中预强化学习模型的基线数据被严重低估了。在相当多的情况下,经过强化学习训练后的模型性能实际上比它们起始时(正确评估的)预强化学习基线还要差。这意味着,这些研究通过强化学习实现的“激发”效果,在没有任何权重更新或微调的情况下同样可以复制。这里,我们指的不是对潜在能力的非标准激发,而仅仅是通过修正提示和生成超参数就能达到的效果。这些修正包括使用正确的格式和更好的答案解析方法,使用推荐的采样温度,使用相同的最大输出token数,以及使用少样本提示来改善格式遵循。如果强化学习训练主要是在教模型更好地适应评估格式,那么它并没有如我们所期望的那样带来新的推理能力。
展望未来,我们希望论文发布时至少能附带在HuggingFace上的开源权重检查点,以及与报告评估数据相对应的模型样本级输出。”
AI创造营AI生活指南