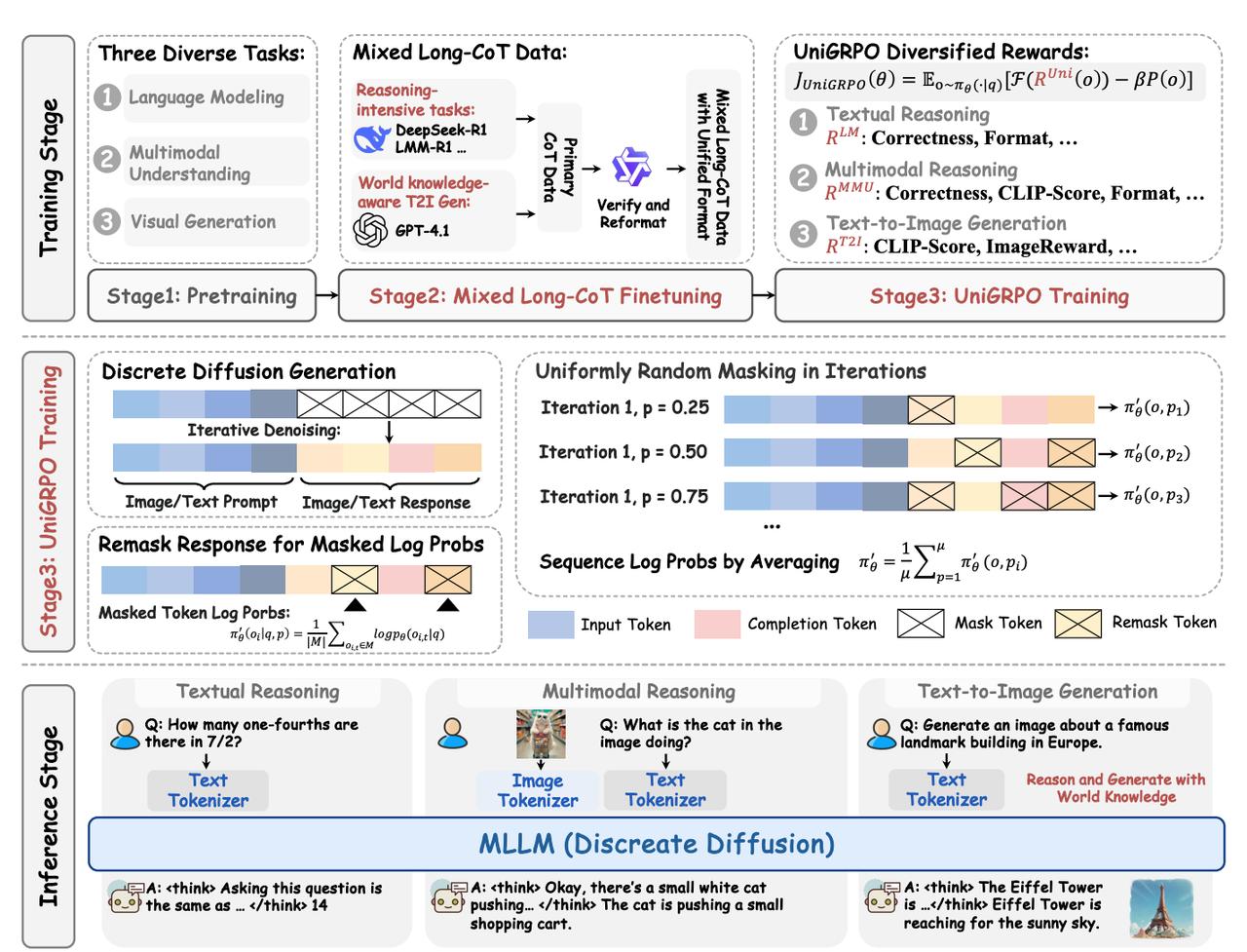
文本生成新范式——扩散大语言模型(dLLM),你听过吗? 普林斯顿大学、字节Seed、北大、清华等团队,搞出来个多模态扩散大语言模型MMaDA。 它首次“扩散模型”用到语言+图像统一建模上,不止能看图说话、文生成图,还能逻辑清晰地“思考”问题。简单说就是:一套模型,三项全能,还都玩得溜。 以前,“扩散模型”主要用在图像生成里(比如 SDXL),现在科研人员把这套方法搬到了语言建模里。 该模型结构紧凑(仅 8B 参数),却在多个评测中实现SOTA表现: - 文本推理:MMLU 准确率超越LLaMA-3-7B、Qwen2-7B; - 多模态理解:POPE、VQAv2等数据集上追平甚至优于Show-o、SEED-X; - 文本到图像生成:CLIP分高达 32.46,图像更符合语义与常识,击败 SDXL 和 Janus。 亮眼成绩的背后,离不开以下三大创新—— 1、统一扩散架构:不再区分“这是图像模型,那是语言模型”,而是把文本和图像统统丢进扩散框架里,统一用离散token表示。这样模型更简单,信息交流也更顺畅。 2、混合长链思考微调(Mixed Long-CoT):引导模型在回答前先“思考”,比如先写出推理过程再给答案。不管是解几何题还是生成带世界知识的图,都更靠谱。 3、UniGRPO 强化学习策略:这是专为扩散模型设计的RL优化方式,解决了扩散训练中掩码比例敏感、生成不稳定等问题。训练过程还加上多种奖励机制,比如图文一致性、格式正确性、人类审美等,帮助模型在不同任务上都表现得更稳更准。 更妙的是,MMaDA不用额外训练就能支持图像修复(inpainting)和外推(extrapolation)。也就是说,无论是文本补一段,还是图像补一角,都能轻松搞定,适应能力特别强。 目前模型、代码和在线Demo都已开源,感兴趣的小伙伴可点击—— 论文: 代码:-Verse/MMaDA 模型:-Verse/MMaDA-8B-Base Demo:-Verse/MMaDA