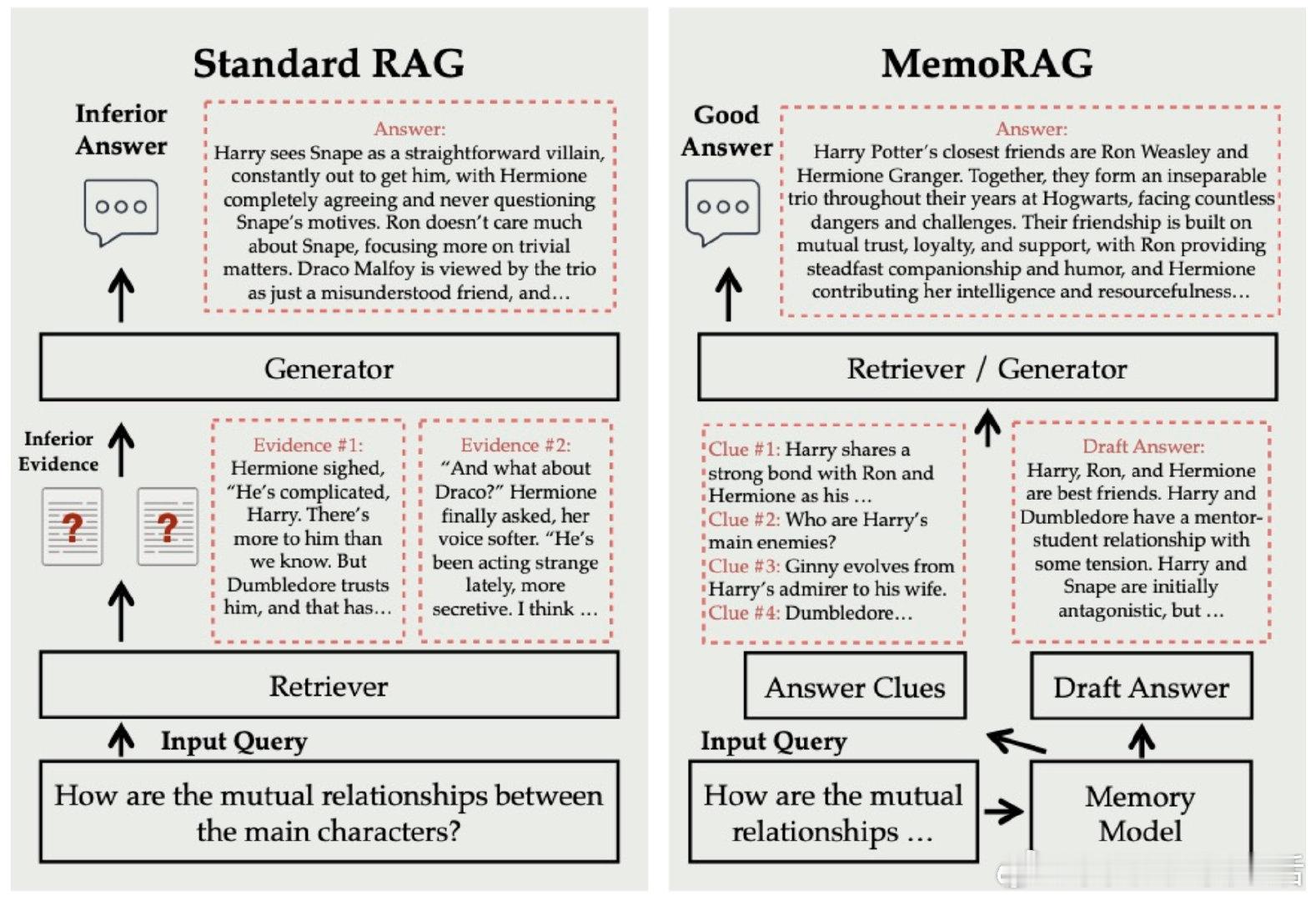
MemoRAG开创了基于记忆的RAG框架,突破传统只针对显式查询的限制,实现对海量数据的全局理解与高效检索:
• 支持单次上下文超百万token,打造超长记忆模型,全面掌控复杂语料📚
• 通过记忆召回生成精准线索,连接原始输入与答案,挖掘深层隐含信息
• 缓存机制加速上下文预填充最高30倍,支持分块索引与重复利用,显著提升效率
• Lite模式仅需少量代码即可快速部署,16-24GiB GPU即可流畅运行,兼容中英文环境
• 灵活适配多种生成模型与检索方式,支持OpenAI和Deepseek API接入,满足多场景需求
• 开源项目持续迭代,论文已获WebConf 2025接收,社区活跃,已有2k+星标和丰富示例代码
• 完善的记忆模型独立使用功能,支持存储、召回、重写查询,提升检索增强的精度和上下文感知
MemoRAG不仅是技术升级,更是对长文本理解与知识发现的根本重塑,助力构建更智能、更高效的RAG系统。
详细内容与Demo👉 github.com/qhjqhj00/MemoRAG
论文链接👉 arxiv.org/abs/2409.05591
人工智能 大模型 长文本理解 知识检索 机器学习 开源项目
![网购有哪些离谱的卡bug经历[捂眼睛]](http://image.uczzd.cn/11603971006175616051.jpg?id=0)


![[doge]Rust程序员的生前幻想(作者:小🍠stellalyRin星澜](http://image.uczzd.cn/11737081896664067047.jpg?id=0)