两图解析注意力机制图解注意力机制优化方案
注意力机制是怎么计算的?两张图就能解释。
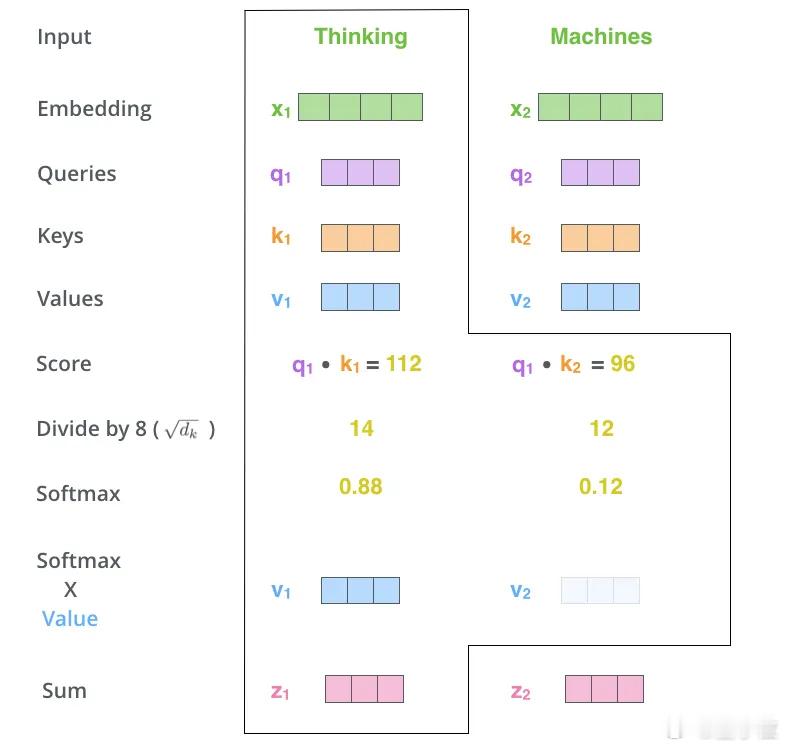
第一张图展示了最基础的注意力机制计算流程:
模型会对每个输入词生成三个向量Query、Key 和 Value。通过Query和所有Key做点积计算“相关性”,再用Softmax得到注意力分布,最后加权所有Value 向量,得到最终输出。
比如,“Thinking”和“Machines”两个词,虽然都参与了计算,但系统更“关注”了前者,因此输出也更偏向于它。这就是经典的Scaled Dot-Product Attention流程。
但这种方式有明显问题:当上下文变长,Key和Value的数量也会线性增加,内存和计算压力迅速飙升。
于是就有了第二张图,对应的是最新的优化方案:MHLA(Multi-Head Latent Attention),用于Deepseek V2等模型中。
它的核心做法是:
- 不再直接存Key/Value,而是先压缩成低维的latent 表示,只存这个;
- 真正使用时,再通过上采样矩阵还原成原始向量;
- 同时位置编码也单独处理,解耦计算,更灵活。
这样做的好处是:
- 大幅降低显存开销,推理速度更快;
- 训练时表现接近传统多头注意力(MHA),但推理效率却像MQ甚至更优。
从最早的MHA到后来的MQA、GQA,再到现在的MHLA,本质上都是在做一件事:让模型更聪明地看,又更省力地记。
这两张图,不仅是计算细节的展示,也是大模型架构优化思路的一个缩影。
参考链接:vinithavn.medium.com/from-multi-head-to-latent-attention-the-evolution-of-attention-mechanisms-64e3c0505f24
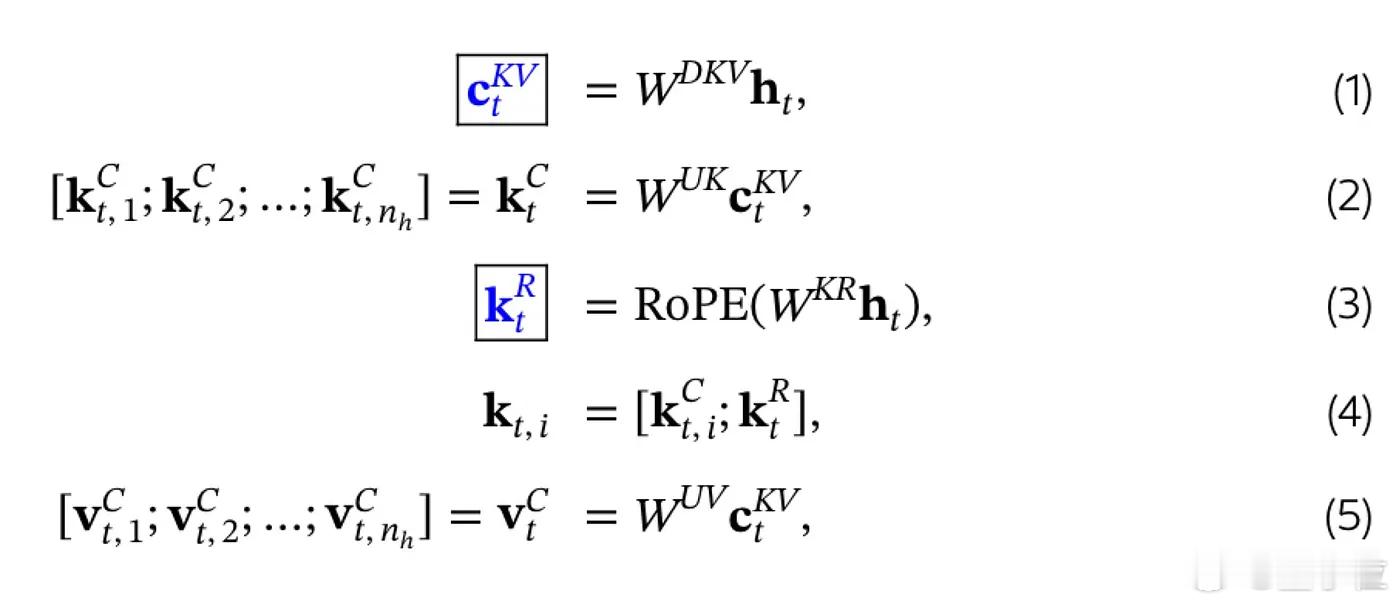
![所以不想要老员工呢,你看侯爷和赵老登那死样[笑着哭][笑着哭][笑着哭]藏](http://image.uczzd.cn/3433128622055031656.jpg?id=0)




![这位靓仔奶丝已经准备好了[doge][doge][doge]今晚见hhh🤣克雷](http://image.uczzd.cn/17443931993771077920.jpg?id=0)


