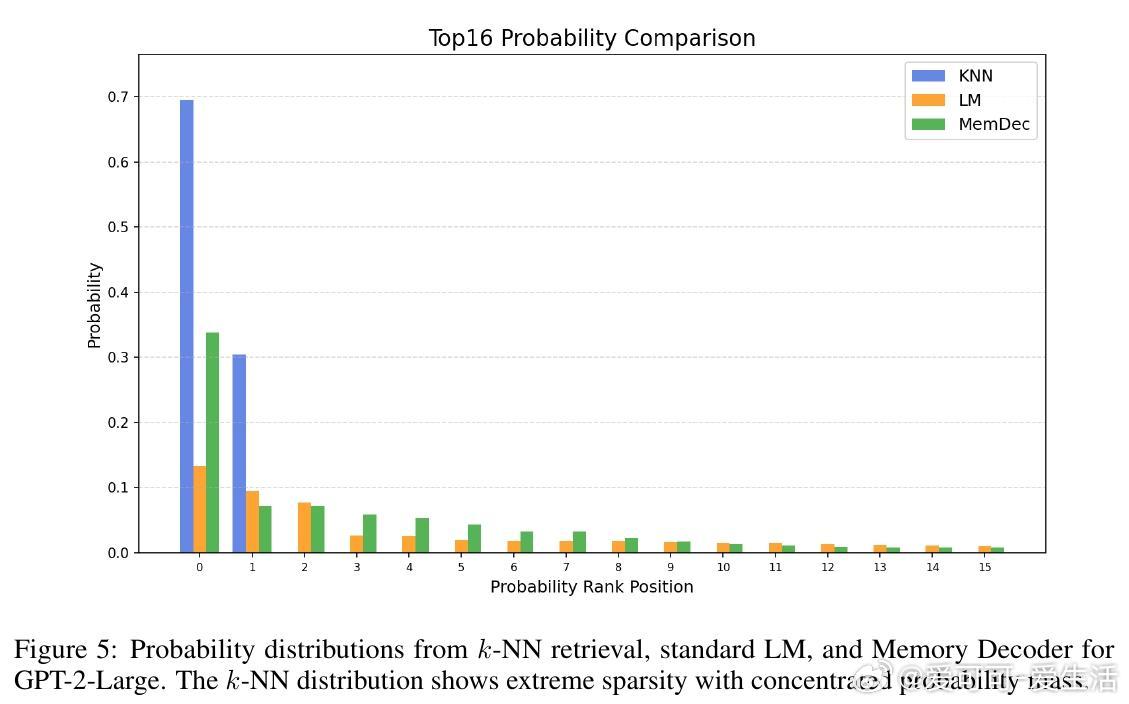
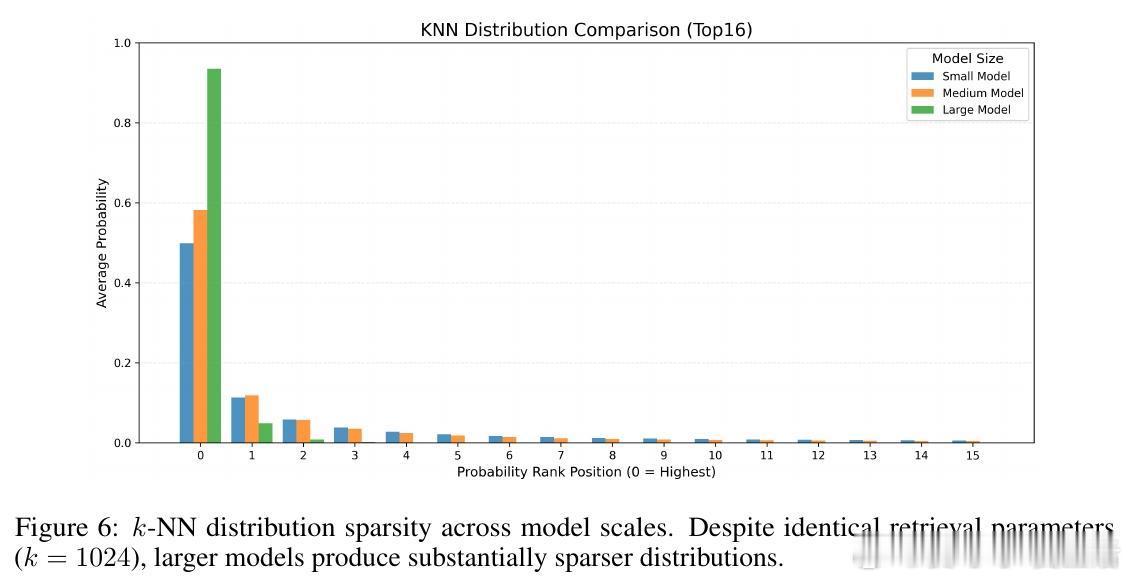
[CL]《Memory Decoder: A Pretrained, Plug-and-Play Memory for Large Language Models》J Cao, J Wang, R Wei, Q Guo... [Shanghai Jiao Tong University] (2025)
Memory Decoder:为大语言模型设计的预训练即插即用记忆模块,实现高效领域自适应
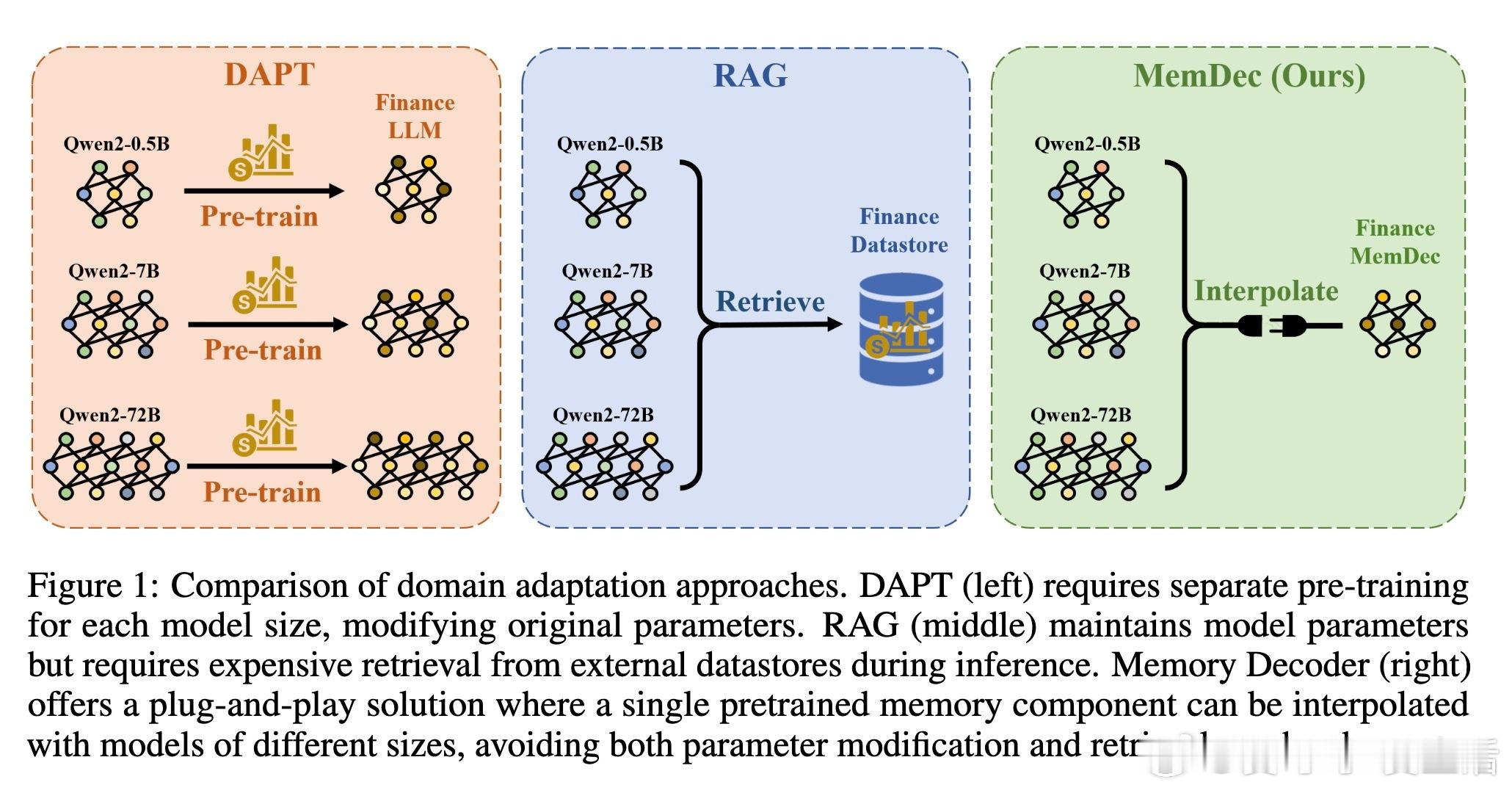
• 解决当前领域适应难题:传统DAPT需全参数训练且成本高,且存在灾难性遗忘;RAG推理时需昂贵的kNN检索,延迟大。Memory Decoder无需修改模型参数,无需检索,兼顾效率与效果。
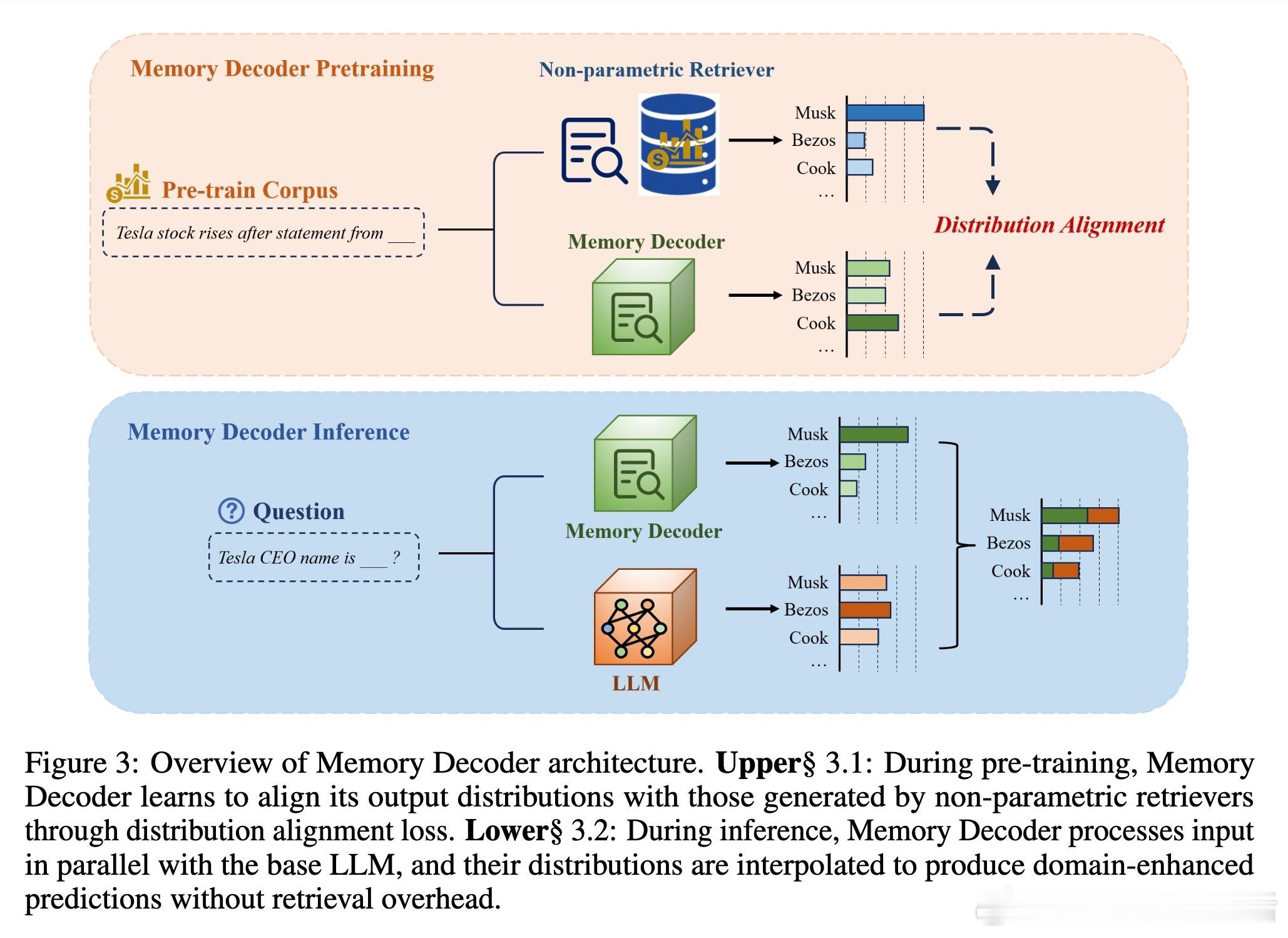
• 架构创新:一个小型Transformer解码器,预训练模仿非参数检索器的输出分布,存储领域知识;推理时与任意同Tokenizer的预训练语言模型并行,输出概率加权融合,实现领域知识注入。
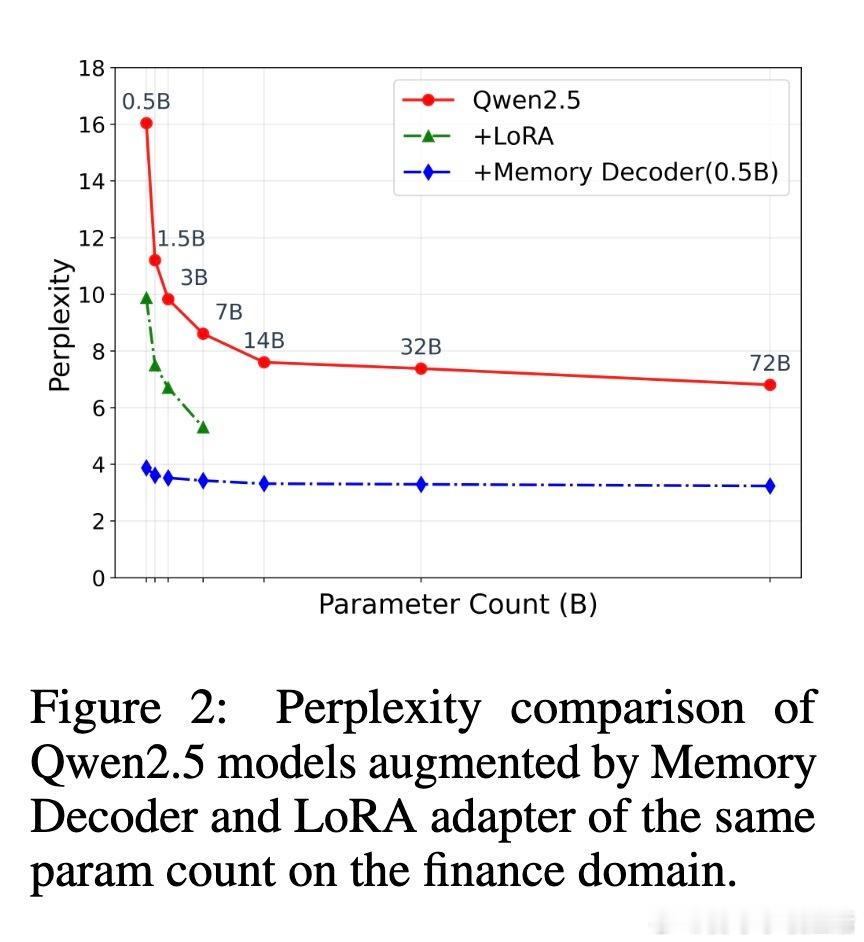
• 跨模型与跨词汇表适应能力强:同一Memory Decoder可无缝增强从0.5B到72B参数的Qwen模型,且可通过小量调优迁移到Llama等不同架构,极大提升实用性和资源利用率。
• 实验覆盖生物医学、金融、法律三大专业领域,多模型、多任务验证,平均困惑度降低6.17,且零样本下保持或提升通用能力,避免了DAPT的灾难性遗忘。
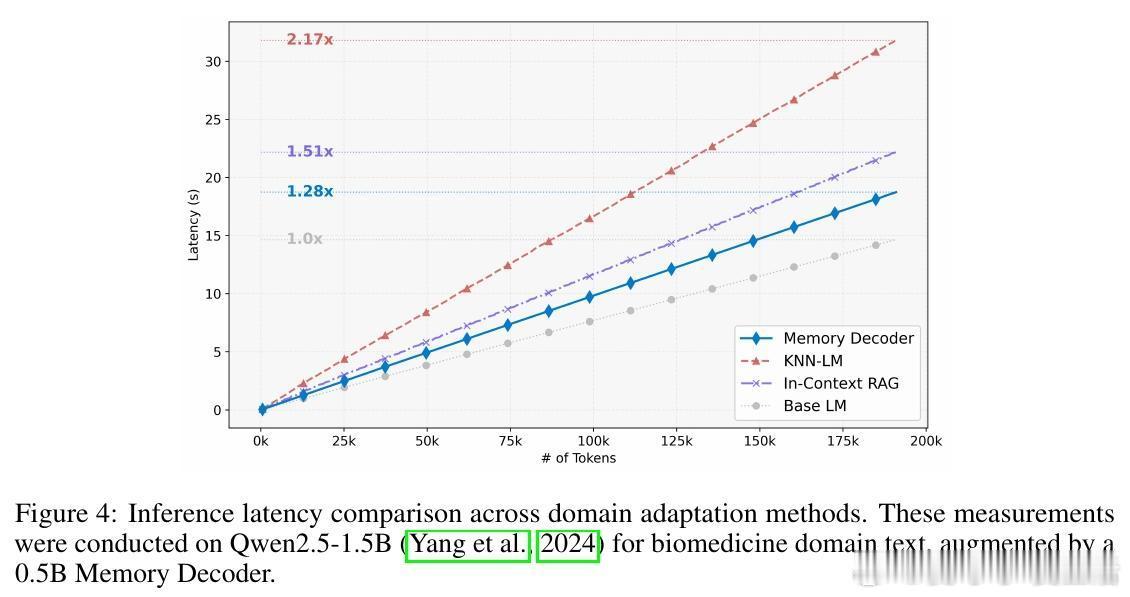
• 推理速度快,推理开销仅1.28×基线,远优于In-Context RAG(1.51×)和kNN-LM(2.17×),存储与计算成本显著下降,适合生产环境部署。
• 训练采用KL散度对齐非参数kNN分布与语言模型交叉熵的混合损失,兼顾知识压缩与语义连贯,验证优于单一目标函数。
• 维护长尾知识记忆和语义连贯性平衡,提升知识密集推理任务表现,克服传统检索方法在复杂推理上的限制。
• 该方法为领域适应开辟新范式:通过独立预训练的记忆模块,实现模块化、参数冻结的领域知识注入,降低多模型多领域适配门槛。
详情阅读👉 arxiv.org/abs/2508.09874
大语言模型领域适应检索增强模型压缩自然语言处理知识注入