随着大型语言模型(LLM)规模和复杂度的指数级增长,推理效率已成为人工智能领域亟待解决的关键挑战。当前,GPT-4、Claude 3和Llama 3等大模型虽然表现出强大的理解与生成能力,但其自回归解码过程中的计算冗余问题依然显著制约着实际应用场景中的响应速度和资源利用效率。
键值(KV)缓存技术作为Transformer架构推理优化的核心策略,通过巧妙地存储和复用注意力机制中的中间计算结果,有效解决了自回归生成过程中的重复计算问题。与传统方法相比,该技术不仅能够在不牺牲模型精度的前提下显著降低延迟,更能实现近线性的计算复杂度优化,为大规模模型部署提供了实用解决方案。
本文将从理论基础出发,系统阐述KV缓存的工作原理、技术实现与性能优势。我们将通过PyTorch实现完整演示代码,详细分析缓存机制如何与Transformer架构的自注意力模块协同工作,并通过定量实验展示不同序列长度下的性能提升。此外,文章还将讨论该技术在实际应用中的局限性及未来优化方向,为读者提供全面而深入的技术洞察。
无论是追求极致推理性能的AI工程师,还是对大模型优化技术感兴趣的研究人员,本文的实践导向方法都将帮助你理解并掌握这一关键性能优化技术。
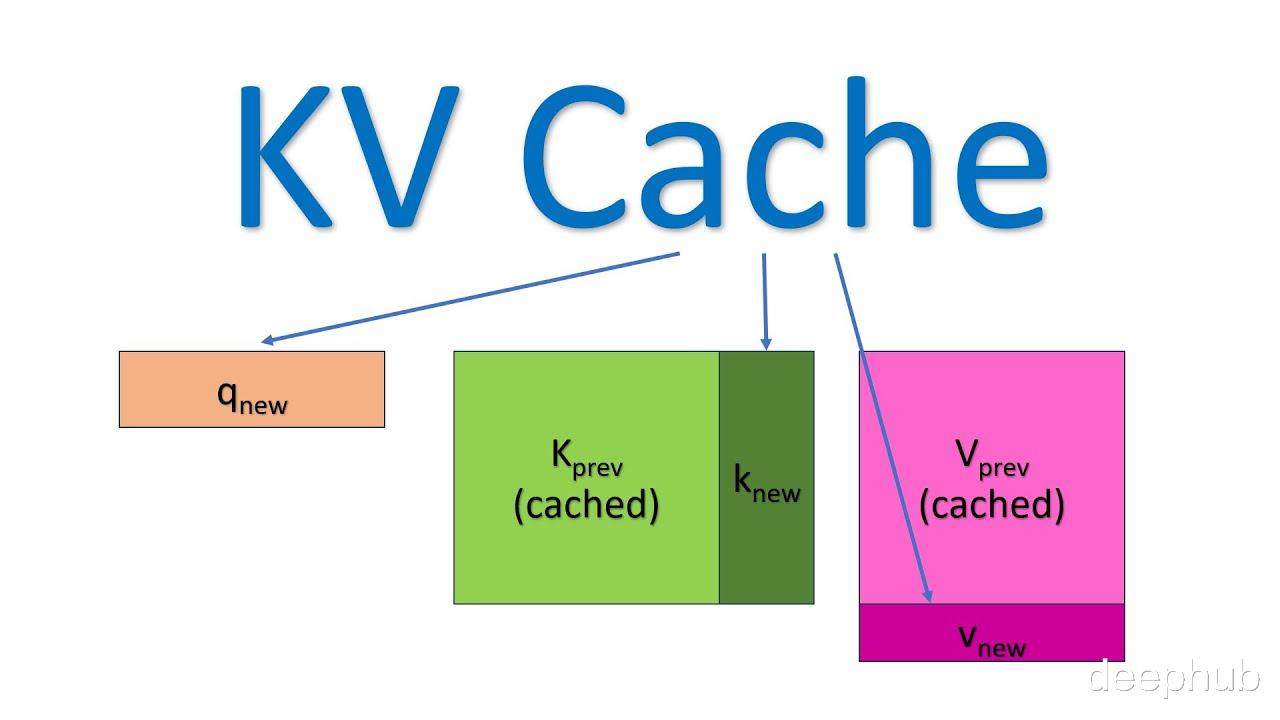
KV缓存是一种优化技术,用于存储注意力机制中已计算的Key和Value张量,这些张量可在后续自回归生成过程中被重复利用,从而有效减少冗余计算,显著提升推理效率。
键值缓存原理注意力机制基础# 多头注意力class MultiHeadAttention(nn.Module): def __init__(self, head_size, num_head): super().__init__() self.sa_head = nn.ModuleList([Head(head_size) for _ in range(num_head)]) self.dropout = nn.Dropout(dropout) self.proj = nn.Linear(embed_size, embed_size) def forward(self, x): x = torch.cat([head(x) for head in self.sa_head], dim= -1) x = self.dropout(self.proj(x)) return x
MultiHeadAttention类的实现遵循标准的多头注意力模块设计。输入张量形状为(B, T, C),其中B代表批次大小,T表示序列长度(在本实现中最大序列长度为block_size),C表示嵌入维度。
多头注意力机制的核心思想是将嵌入空间划分为多个头,每个头独立计算注意力权重。对于嵌入维度C=128且头数量为4的情况,每个头的维度为128/4=32。系统将分别计算这4个大小为32的注意力头,然后将结果拼接成形状为(B, T, 128)的输出张量。
KV缓存的必要性为理解KV缓存的必要性,首先需要分析注意力机制的计算过程:
class Head(nn.Module): def __init__(self, head_size): super().__init__() self.head_size = head_size self.key = nn.Linear(embed_size, head_size, bias=False) self.query = nn.Linear(embed_size, head_size, bias=False) self.value = nn.Linear(embed_size, head_size, bias=False) self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size))) self.dropout = nn.Dropout(dropout) def forward(self, x): B, T, C = x.shape k = self.key(x) q = self.query(x) v = self.value(x) wei = q@k.transpose(2, 1)/self.head_size**0.5 wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) wei = F.softmax(wei, dim=2) # (B , block_size, block_size) wei = self.dropout(wei) out = wei@v return out
在注意力头的实现中,系统通过线性变换生成Key、Value和Query,它们的形状均为(B, T, C),其中C为头的大小。
Query与Key进行点积运算,生成形状为(B, T, T)的权重矩阵,表示各token之间的相关性。权重矩阵经过掩码处理转换为下三角矩阵,确保在点积运算过程中每个token仅考虑前面的token(即从1到n),这强制实现了因果关系,使得自回归模型中的token仅使用历史信息预测下一个token。
下图展示了自回归生成在注意力机制中的实现过程:
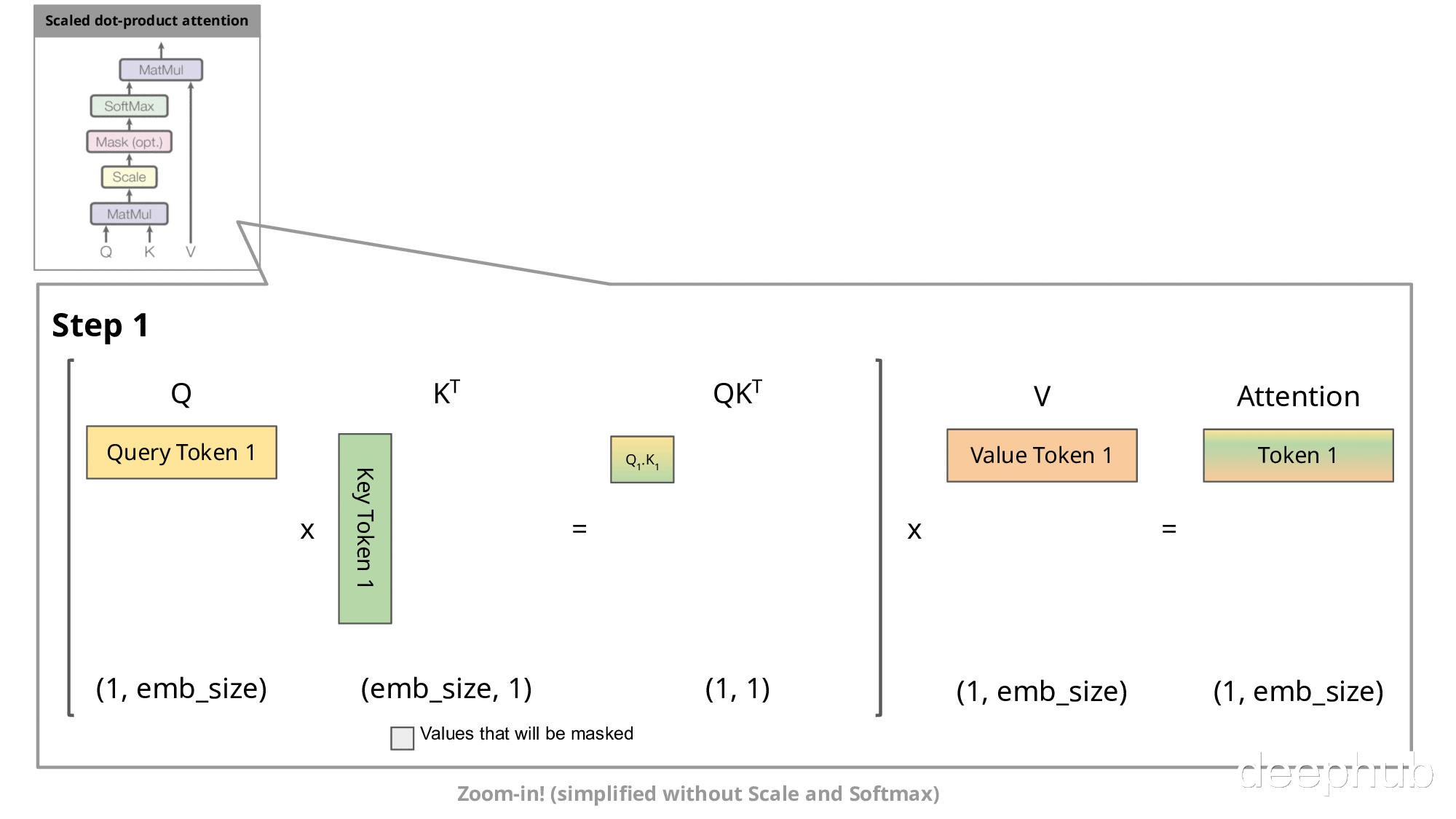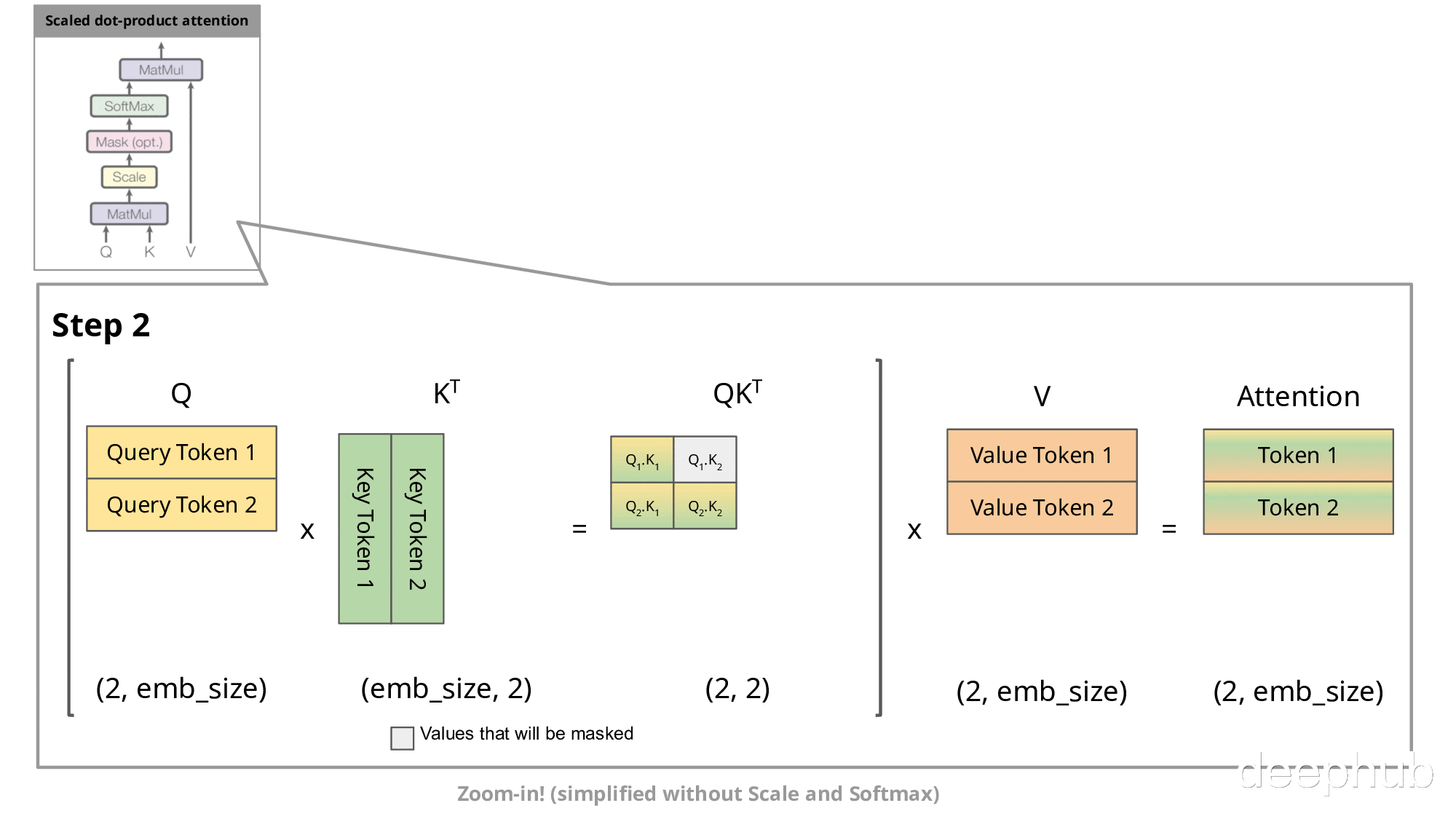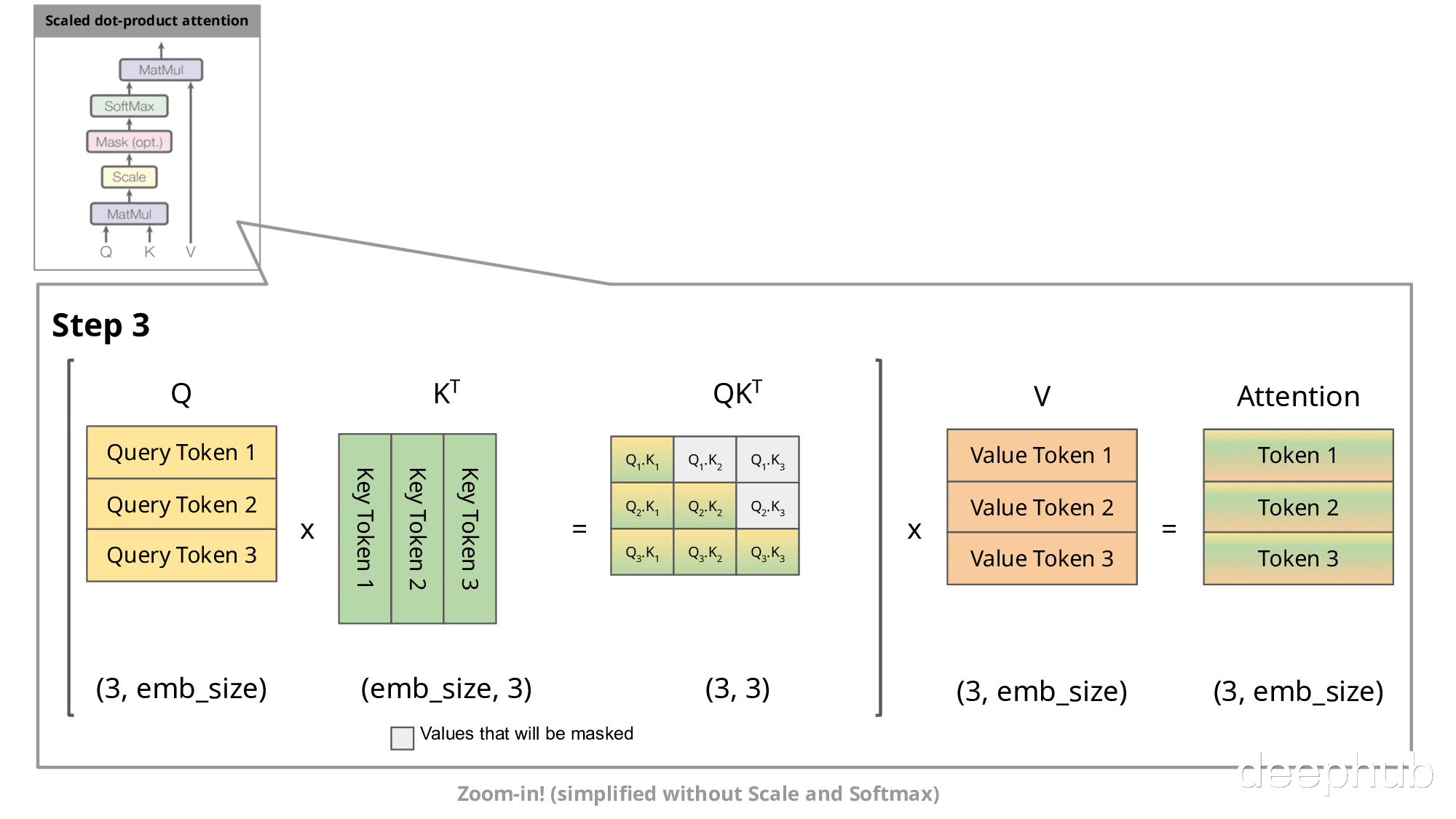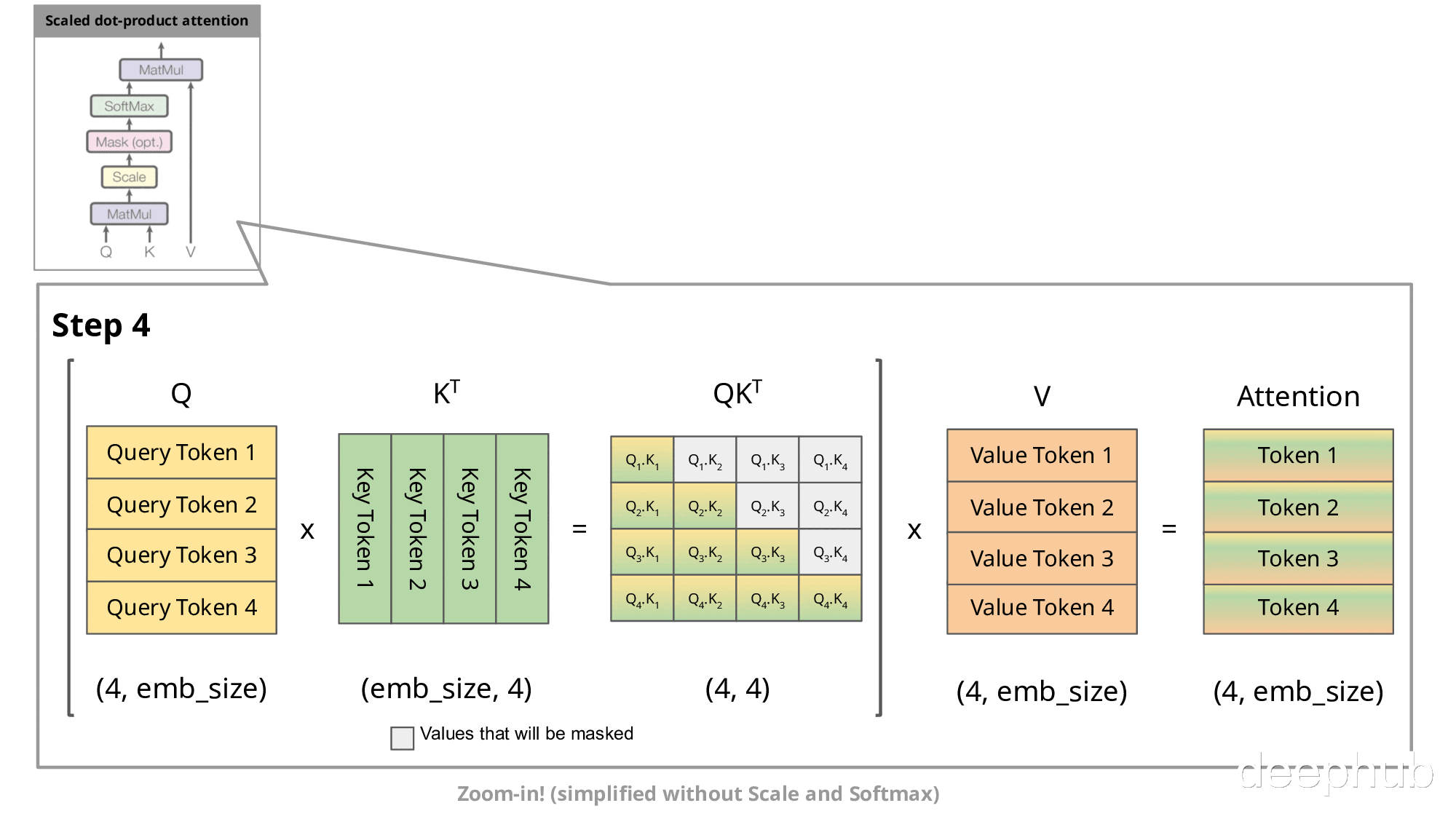
在自回归生成的每个步骤中,系统均需重新计算已经计算过的Key和Value。例如,在第2步中,K1与第1步生成的K1相同。由于在推理阶段模型参数已固定,相同输入将产生相同输出,因此将这些Key和Value存储在缓存中并在后续步骤中复用是更高效的方法。
下图直观展示了KV缓存的工作机制:
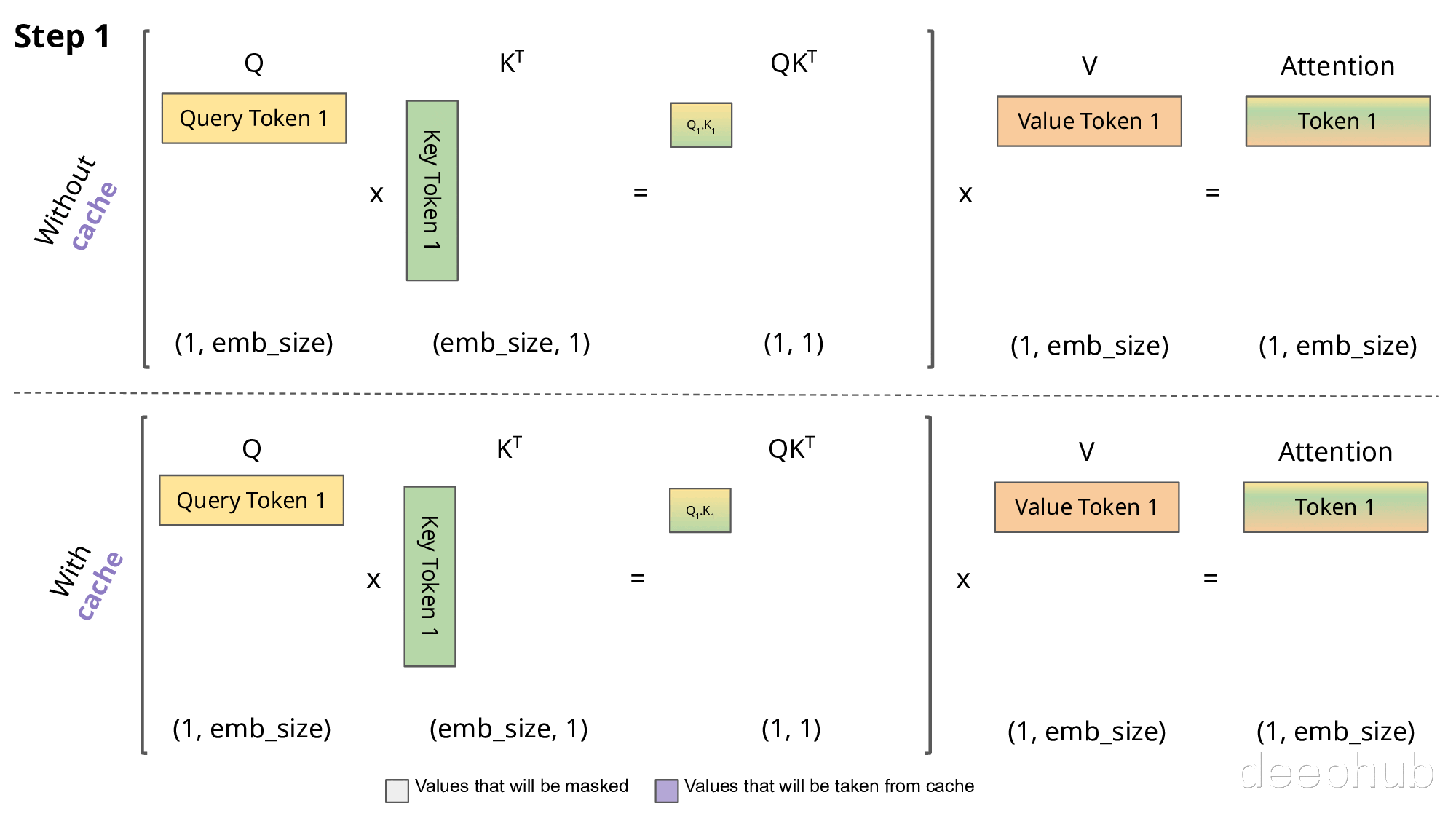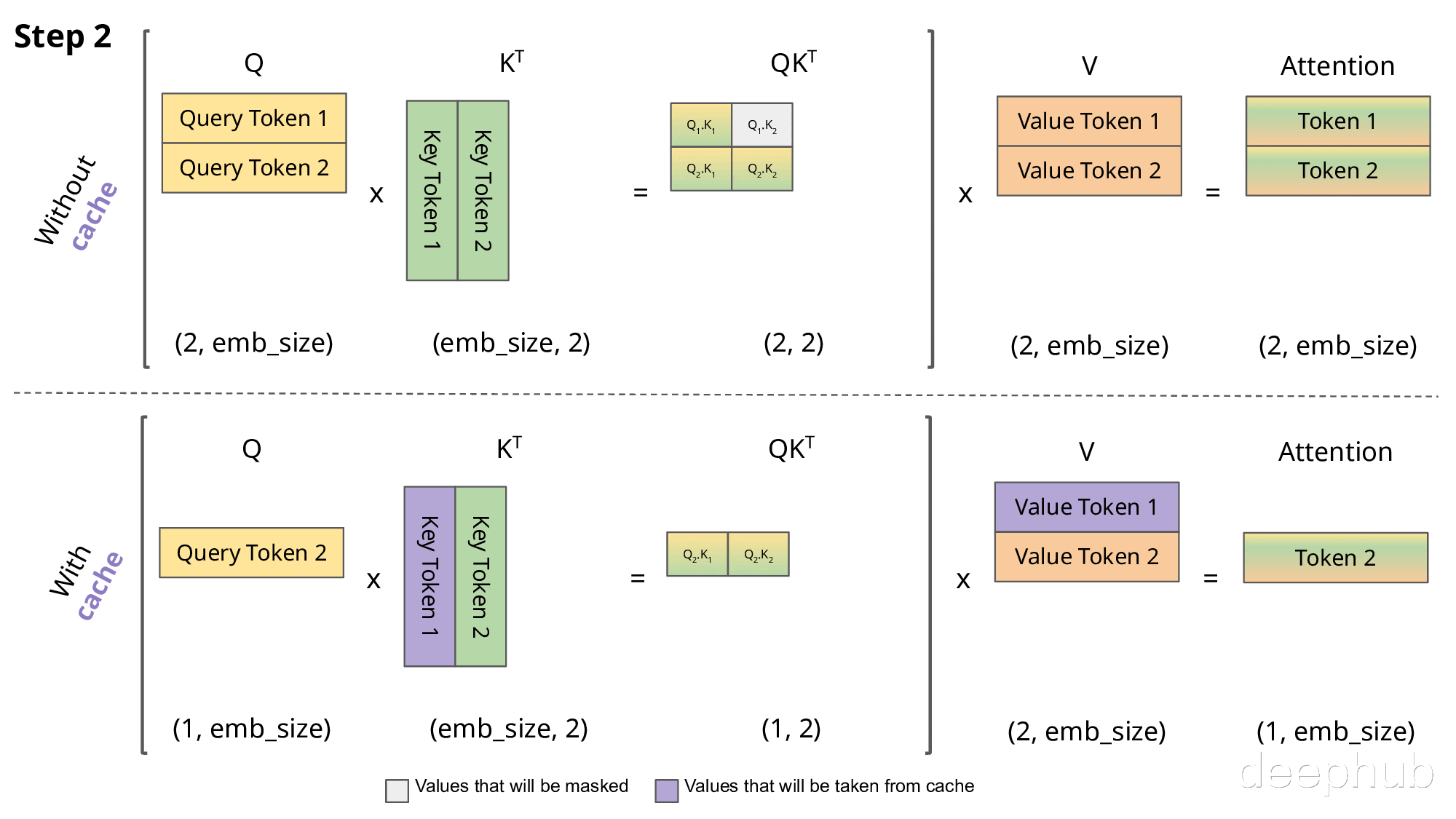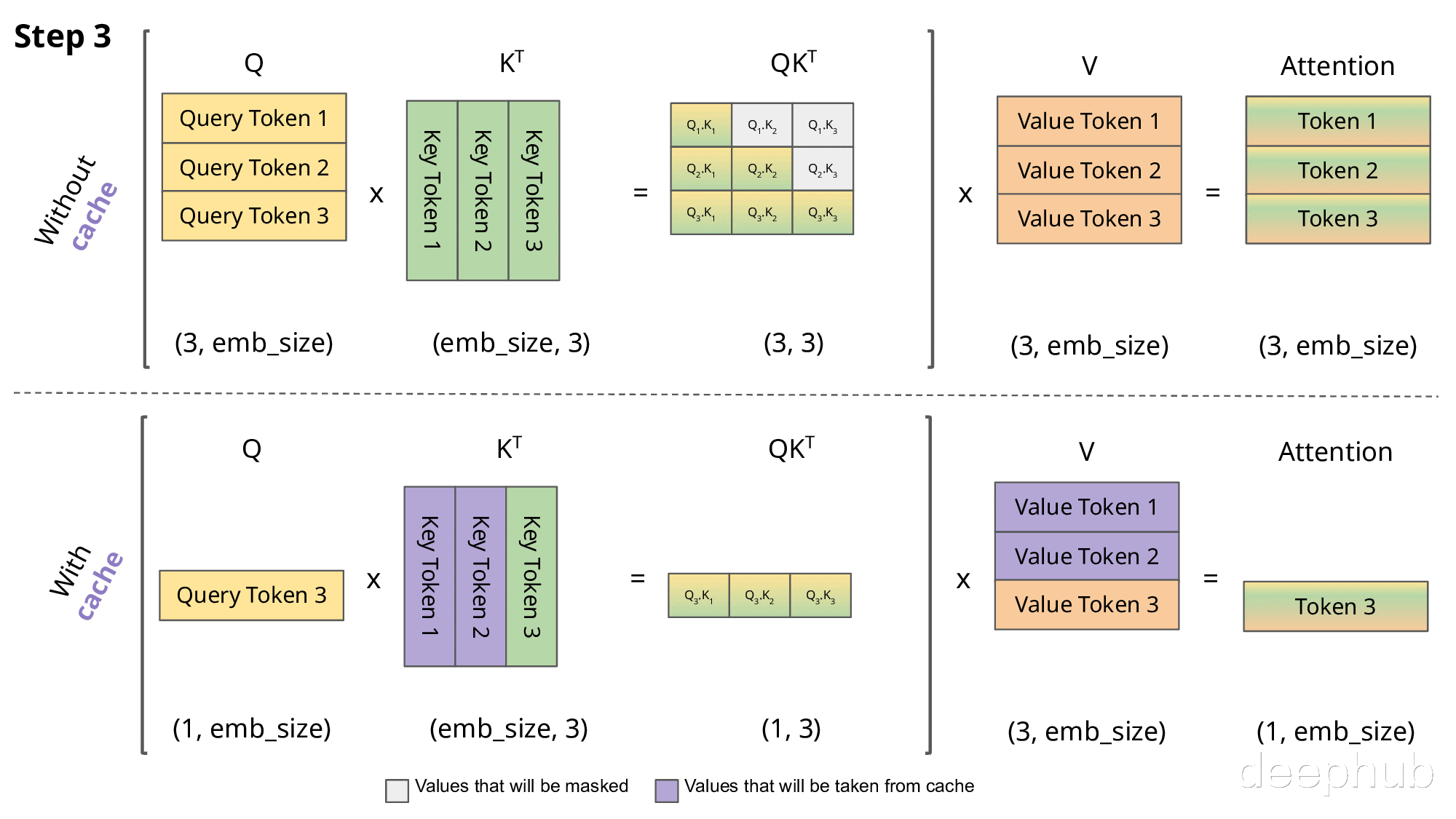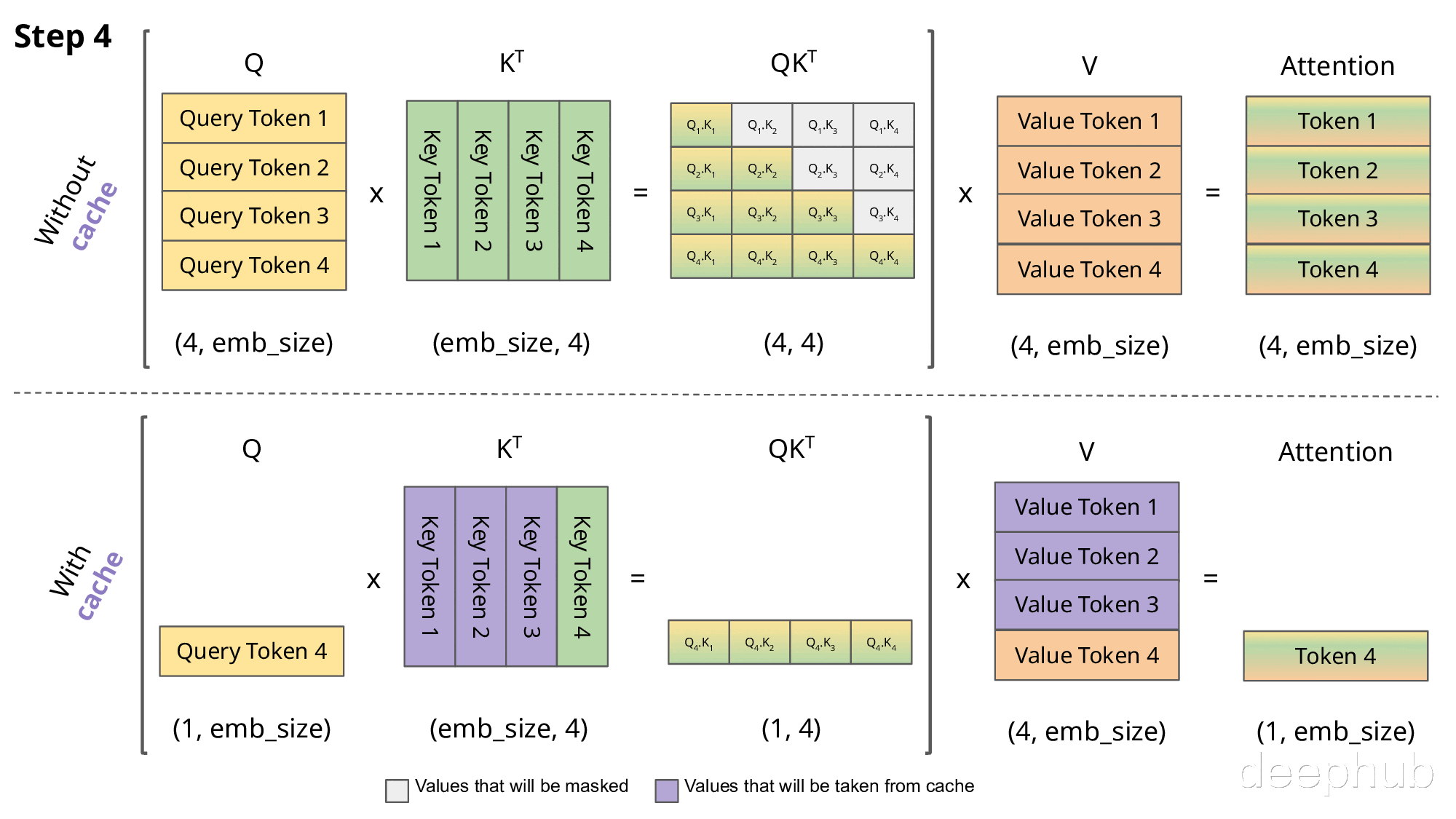
实现KV缓存的主要区别在于:
推理时每次仅传入一个新token,而非增量传递所有token
由于Key和Value已缓存,无需重复计算历史token的表示
无需对权重进行掩码处理,因为每次只处理单个Query token,权重矩阵(QK^T)的维度为(B, 1, T)而非(B, T, T)
缓存机制实现KV缓存的实现基于形状为(B, T, C)的零张量初始化,其中T为最大处理的token数量(即block_size):
class Head(nn.Module): def __init__(self, head_size): super().__init__() self.head_size = head_size self.key = nn.Linear(embed_size, head_size, bias=False) self.query = nn.Linear(embed_size, head_size, bias=False) self.value = nn.Linear(embed_size, head_size, bias=False) self.dropout = nn.Dropout(dropout) self.k_cache = None self.v_cache = None self.cache_index = 0 def forward(self, x): B, T, C = x.shape # 形状: B, 1, C k = self.key(x) q = self.query(x) v = self.value(x) # 如果缓存为空则初始化 if self.k_cache is None or self.v_cache is None: # 使用固定大小初始化缓存 self.k_cache = torch.zeros(B, block_size, self.head_size, device=x.device) self.v_cache = torch.zeros(B, block_size, self.head_size, device=x.device) self.cache_index = 0 return out
自回归模型在训练时使用固定的上下文长度,即当前token预测下一个token时可回溯的最大token数量。在本实现中,这个上下文长度由block_size参数确定,表示缓存的最大token数量,通过缓存索引进行跟踪:
def forward(self, x): B, T, C = x.shape # B, 1, C k = self.key(x) q = self.query(x) v = self.value(x) # 如果缓存为空则初始化 if self.k_cache is None or self.v_cache is None: # 使用固定大小初始化缓存 self.k_cache = torch.zeros(B, block_size, self.head_size, device=x.device) self.v_cache = torch.zeros(B, block_size, self.head_size, device=x.device) self.cache_index = 0 # 原地更新缓存 if self.cache_index + T <= block_size: self.k_cache[:, self.cache_index:self.cache_index + T, :] = k self.v_cache[:, self.cache_index:self.cache_index + T, :] = v # 注意:鉴于我们一次只传递一个token,T将始终为1,因此上面的操作 # 等效于直接执行self.k_cache[:, self.cache_index, :] = k # 更新缓存索引 self.cache_index = min(self.cache_index + T, block_size) # 注意力点积 wei = q@self.k_cache.transpose(2, 1)/self.head_size**0.5 wei = F.softmax(wei, dim=2) # (B, block_size, block_size) wei = self.dropout(wei) out = wei@self.v_cache return out
从第一个token开始,系统将Key-Value对存入对应的缓存位置,并递增缓存索引直到达到设定的上限:
def forward(self, x): B, T, C = x.shape # B, 1 (T), C k = self.key(x) q = self.query(x) v = self.value(x) if self.k_cache is None or self.v_cache is None: # 使用固定大小初始化缓存 self.k_cache = torch.zeros(B, block_size, self.head_size, device=x.device) self.v_cache = torch.zeros(B, block_size, self.head_size, device=x.device) self.cache_index = 0 # 原地更新缓存 if self.cache_index + T <= block_size: self.k_cache[:, self.cache_index:self.cache_index + T, :] = k self.v_cache[:, self.cache_index:self.cache_index + T, :] = v else: # 将token向后移动一步 shift = self.cache_index + T - block_size # Shift将始终为1 self.k_cache[:, :-shift, :] = self.k_cache[:, shift:, :].clone() self.v_cache[:, :-shift, :] = self.v_cache[:, shift:, :].clone() self.k_cache[:, -T:, :] = k self.v_cache[:, -T:, :] = v # 更新缓存索引 self.cache_index = min(self.cache_index + T, block_size) wei = q@self.k_cache.transpose(2, 1)/self.head_size**0.5 wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) wei = F.softmax(wei, dim=2) # (B, block_size, block_size) wei = self.dropout(wei) out = wei@self.v_cache return out
当缓存索引达到block_size时,系统会将所有token向前移动一个位置,为新token腾出空间,并将新token分配到最后一个位置:
# 缓存移动示例k_cache = torch.zeros(1, 3, 3)v_cache = torch.zeros(1, 3, 3)steps = 3for i in range(steps): k_cache[:, i, :] = torch.randint(10, (1, 3))print("k_cache Before:\n", k_cache)shift = 1k_cache[:, :-shift, :] = k_cache[:, shift:, :].clone()v_cache[:, :-shift, :] = v_cache[:, shift:, :].clone()print("k_cache After:\n", k_cache)# 输出 :-k_cache Before: tensor([[[2., 2., 9.], [3., 6., 4.], [3., 9., 5.]]])k_cache After: tensor([[[3., 6., 4.], [3., 9., 5.], [3., 9., 5.]]]) # 这个最后的token随后被新的Key Token k_cache[:, -T:, :] = k替换
以上即为KV缓存在注意力机制中的完整实现。接下来我们将分析KV缓存对推理性能的具体影响。
推理性能比较本节将展示KV缓存优化技术对推理性能的实际影响。以下是实现了KV缓存的GPT模型代码:
# 导入库import torchimport torch.nn as nnfrom torch.nn import functional as F# 读取txt文件(编码解码)/* 从以下地址下载:https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt */text = open('input.txt', 'r',).read()vocab = sorted(list(set(text)))encode = lambda s: [vocab.index(c) for c in s]decode = lambda l: [vocab[c] for c in l]# 划分训练集和验证集x = int(0.9*len(text))text = torch.tensor(encode(text), dtype=torch.long)train, val = text[:x], text[x:]# 创建一个get_batch函数以(batch_size, vocab_size(8))的形状从文本中随机加载数据device = 'cuda' if torch.cuda.is_available() else 'cpu'torch.manual_seed(1337)batch_size = 8 # 我们将并行处理多少个独立序列?block_size = 1024 # 预测的最大上下文长度?embed_size = 256dropout = 0num_head = 4num_layers = 4def get_batch(split): # 生成一小批输入x和目标y的数据 data = train if split == 'train' else val ix = torch.randint(len(data) - block_size, (batch_size,)) x = torch.stack([data[i:i+block_size] for i in ix]) y = torch.stack([data[i+1:i+block_size+1] for i in ix]) return x.to(device), y.to(device)xb, yb = get_batch('train')# 注意力头class Head(nn.Module): def __init__(self, head_size): super().__init__() self.head_size = head_size self.key = nn.Linear(embed_size, head_size, bias=False) self.query = nn.Linear(embed_size, head_size, bias=False) self.value = nn.Linear(embed_size, head_size, bias=False) self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size))) self.dropout = nn.Dropout(dropout) def forward(self, x): B, T, C = x.shape k = self.key(x) q = self.query(x) v = self.value(x) wei = q@k.transpose(2, 1)/self.head_size**0.5 wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) wei = F.softmax(wei, dim=2) # (B , block_size, block_size) wei = self.dropout(wei) out = wei@v return out# 多头注意力class MultiHeadAttention(nn.Module): def __init__(self, head_size, num_head): super().__init__() self.sa_head = nn.ModuleList([Head(head_size) for _ in range(num_head)]) self.dropout = nn.Dropout(dropout) self.proj = nn.Linear(embed_size, embed_size) def forward(self, x): x = torch.cat([head(x) for head in self.sa_head], dim= -1) x = self.dropout(self.proj(x)) return xclass FeedForward(nn.Module): def __init__(self, embed_size): super().__init__() self.ff = nn.Sequential( nn.Linear(embed_size, 4*embed_size), nn.ReLU(), nn.Linear(4*embed_size, embed_size), nn.Dropout(dropout) ) def forward(self, x): return self.ff(x)class Block(nn.Module): def __init__(self, embed_size, num_head): super().__init__() head_size = embed_size // num_head self.multihead = MultiHeadAttention(head_size, num_head) self.ff = FeedForward(embed_size) self.ll1 = nn.LayerNorm(embed_size) self.ll2 = nn.LayerNorm(embed_size) def forward(self, x): x = x + self.multihead(self.ll1(x)) x = x + self.ff(self.ll2(x)) return x# 超简单的bigram模型class BigramLanguageModelWithCache(nn.Module): def __init__(self, vocab_size): super().__init__() # 每个token直接从查找表中读取下一个token的logits self.token_embedding_table = nn.Embedding(vocab_size, embed_size) self.possitional_embedding = nn.Embedding(block_size, embed_size) self.linear = nn.Linear(embed_size, vocab_size) self.block = nn.Sequential(*[Block(embed_size, num_head) for _ in range(num_layers)]) self.layer_norm = nn.LayerNorm(embed_size) def forward(self, idx, targets=None): B, T = idx.shape # idx和targets都是(B,T)整数张量 logits = self.token_embedding_table(idx) # (B,T,C) ps = self.possitional_embedding(torch.arange(T, device=device)) x = logits + ps #(B, T, C) logits = self.block(x) #(B, T, c) logits = self.linear(self.layer_norm(logits)) # 这应该在head_size和Vocab_size之间进行映射 if targets is None: loss = None else: B, T, C = logits.shape logits = logits.view(B*T, C) targets = targets.view(B*T) loss = F.cross_entropy(logits, targets) return logits, loss def generate(self, idx, max_new_tokens): # idx是当前上下文中索引的(B, T)数组 for _ in range(max_new_tokens): # 获取预测结果 logits, loss = self(idx) # logits形状:B, 1, C logits = logits[:, -1, :] # 变为(B, C) # 应用softmax获取概率 probs = F.softmax(logits, dim=-1) # (B, C) # 从分布中采样 idx_next = torch.multinomial(probs, num_samples=1).to(device) # (B, 1) # 无需拼接,因为我们一次只传递一个token idx = idx_next return idx
generate函数在推理阶段被显式调用,不参与训练过程:
m_kv_cache = BigramLanguageModelWithCache(65).to(device)m_kv_cache.load_state_dict(torch.load("bigram.pth"))
通过执行generate命令可以测量KV缓存对推理性能的影响:
m_kv_cache = BigramLanguageModelWithCache(65).to(device)steps = 10000print("".join(decode(m_kv_cache.generate(torch.zeros([1,1], dtype=torch.long).to(device) , max_new_tokens=steps)[0].tolist())))
下图展示了标准模型与KV缓存模型在不同生成步数下的推理时间对比,测试模型的序列长度(block_size)为1024,嵌入维度为256:
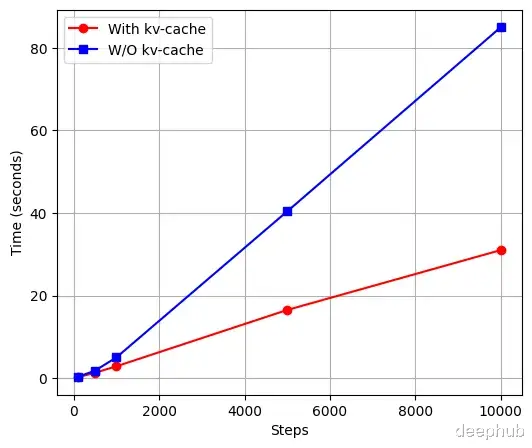
# 数据点steps = [100, 500, 1000, 5000, 10000]kv-cache = [0.2, 1.3, 2.85, 16.5, 31] # 红线w/0 kv-cache = [0.3, 1.8, 5.01, 40.4, 85] # 蓝线
实验结果表明,KV缓存模型在推理性能上总体优于标准模型,但其效率取决于浮点运算次数(FLOPs),而FLOPs会随着序列长度(block_size)和嵌入维度(embed_size)的增加而增加。对于较小的模型配置(如block_size=8, embed_size=64),标准模型可能更高效。由于计算复杂度随模型大小增加,KV缓存的优势在大型模型中更为明显。有关标准Transformer与KV缓存模型的FLOPs计算详情,可参考Rajan的技术文章[2]。
以下是生成的输出示例:
TRUCEMIM-y vit s.PETRO: histe feRil ass:Whit Cimovecest isthen iduche neesoxlg anouther ankes aswerclin'swal k s with selon more stoflld noncr id, mcis heis,A?TIOinkbupt venonn, d Ce?teyKe thiston tiund thorn fethe sutan kiportanou wuth thas tthers, steiellellke, on s hyou trefit.Bwat dotive wother, foru;Anke; ineees ronon irun: heals, I it Heno; gedad n thouc e,on pind ttanof anontoay:Isher!Ase, mesev minds
需要注意的是,生成的文本看似无意义,但这主要是由于计算资源和训练数据的限制,而非KV缓存技术本身的问题。尽管标准模型能生成更接近真实英语的单词,但KV缓存模型仍保留了基本的结构特征,只是输出质量有所降低。
最后,我们使用Hugging Face的预训练GPT-2模型进行了对比测试:
from transformers import AutoModelForCausalLM, AutoTokenizerimport time# 加载模型和分词器model_name = "gpt2"model = AutoModelForCausalLM.from_pretrained(model_name)tokenizer = AutoTokenizer.from_pretrained(model_name)# 文本提示prompt = "Once upon a time"input_ids = tokenizer(prompt, return_tensors="pt").input_ids# 生成文本并测量时间的函数def generate_text(use_cache): # 生成文本 start_time = time.time() output_ids = model.generate(input_ids.to(device), use_cache=use_cache, max_new_tokens=1000) elapsed_time = time.time() - start_time # 解码输出 output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True) return output_text, elapsed_time# 不使用KV缓存生成output_without_cache, time_without_cache = generate_text(use_cache=False)print("Without KV Cache:")print(output_without_cache)print(f"Time taken: {time_without_cache:.2f} seconds\n")# 使用KV缓存生成output_with_cache, time_with_cache = generate_text(use_cache=True)print("With KV Cache:")print(output_with_cache)print(f"Time taken: {time_with_cache:.2f} seconds")
测试结果:
Without KV Cache:Once upon a time, the world was a place of great beauty and great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the world was a place of great danger.Time taken: 76.70 secondsWith KV Cache:Once upon a time, the world was a place of great beauty and great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the world was a place of great danger.Time taken: 62.46 seconds
总结本文详细阐述了KV缓存的工作原理及其在大型语言模型推理优化中的应用,文章不仅从理论层面阐释了KV缓存的工作原理,还提供了完整的PyTorch实现代码,展示了缓存机制与Transformer自注意力模块的协同工作方式。实验结果表明,随着序列长度增加,KV缓存技术的优势愈发明显,在长文本生成场景中能将推理时间降低近60%。这一技术为优化大模型部署提供了一种无需牺牲精度的实用解决方案,为构建更高效的AI应用奠定了基础。
https://avoid.overfit.cn/post/3e49427b9e42440aa0c8d834c1906f2f
作者:Shubh Mishra