[CL]《REFRAG: Rethinking RAG based Decoding》X Lin, A Ghosh, B K H Low, A Shrivastava... [Meta Superintelligence Labs & National University of Singapore] (2025)
REFRAG:颠覆传统RAG解码,极大提升长上下文推理效率
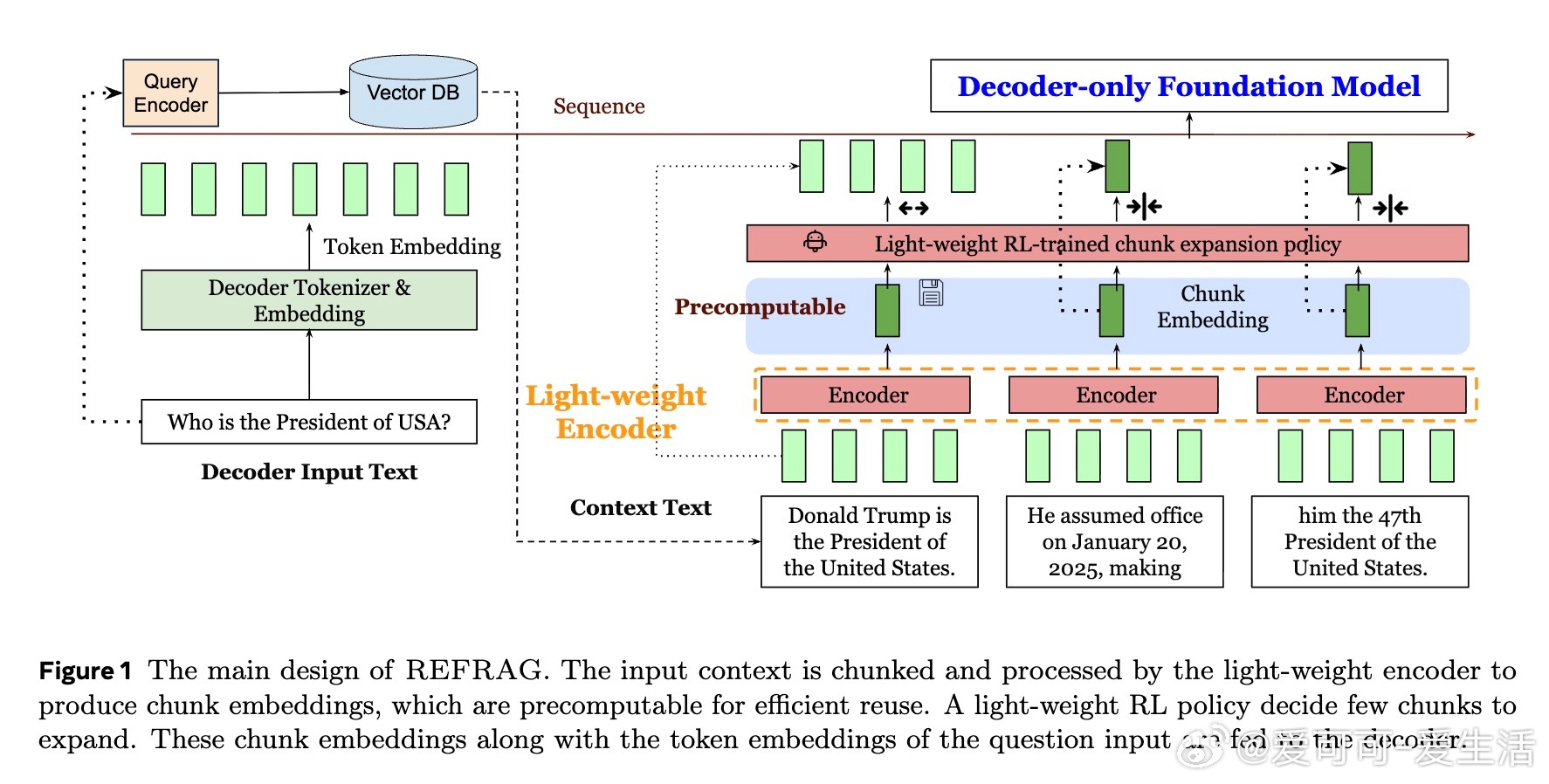
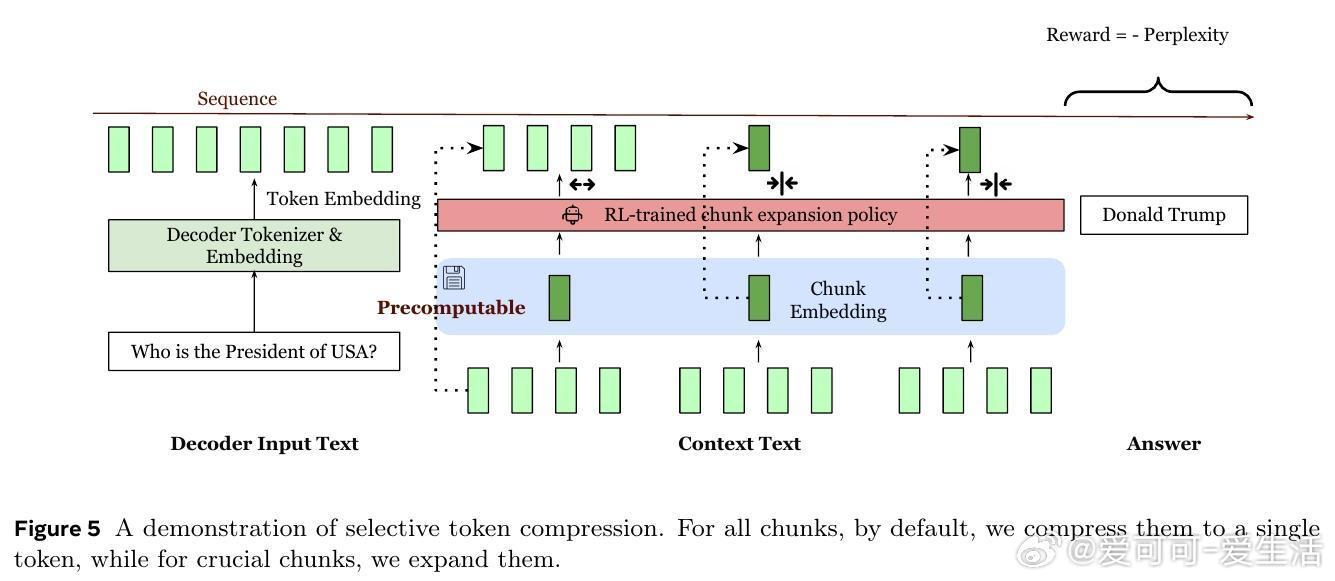
• 通过压缩、感知和扩展机制,REFRAG利用RAG上下文中检索片段间注意力的稀疏结构,将解码输入从逐token降低为按chunk嵌入,显著缩短输入序列长度。
• 采用轻量级编码器(如RoBERTa)预计算并缓存chunk嵌入,减少重复计算;引入强化学习策略动态选择关键chunk展开,全局保留自回归性质。
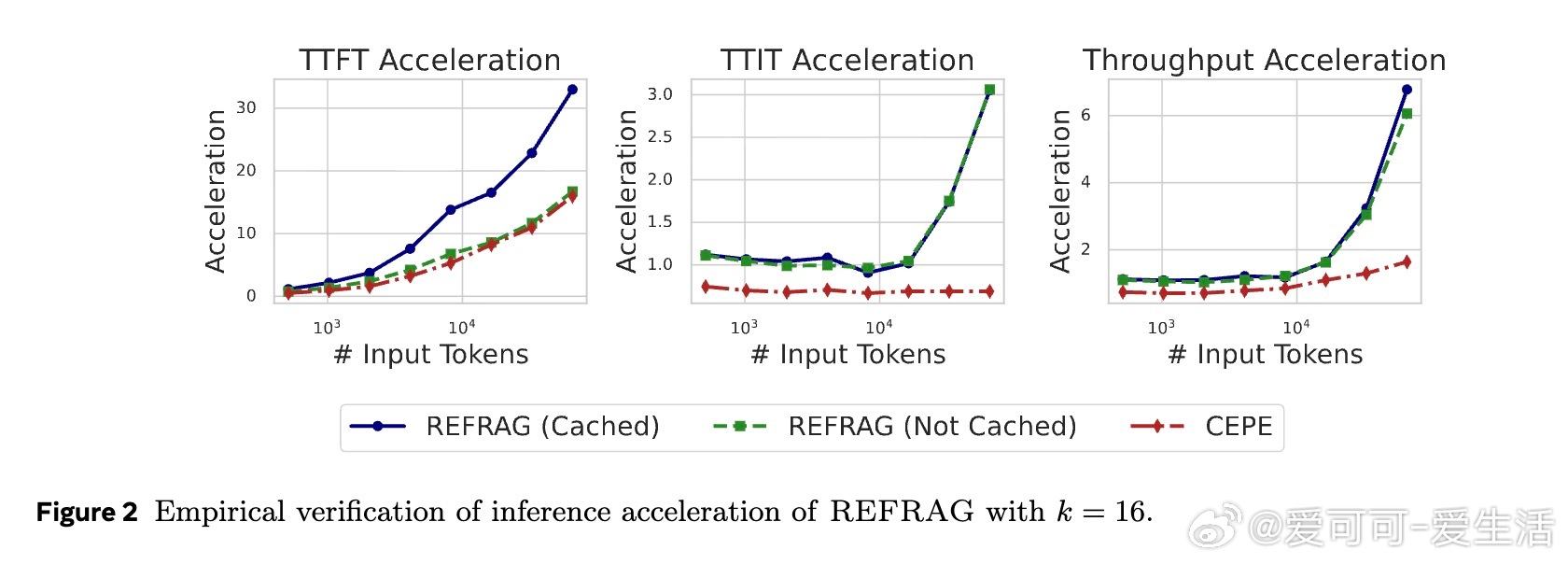
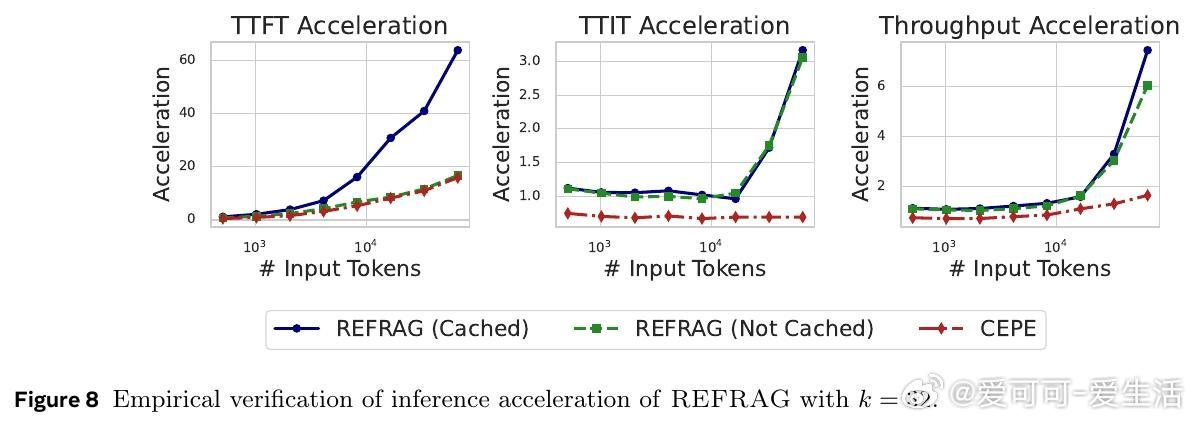
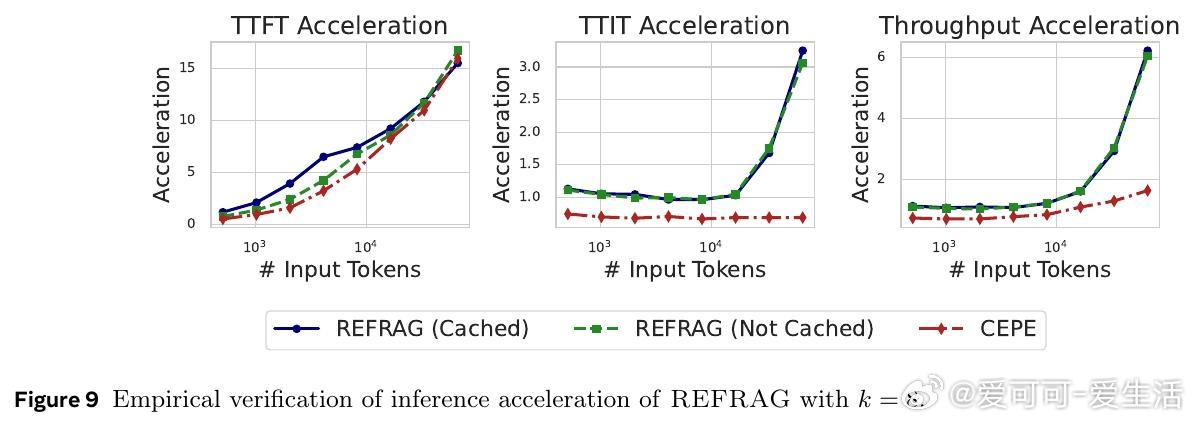
• 实现TTFT(首token生成时间)最高30.85×加速(相较于LLaMA),且无困惑度和下游任务性能损失;支持上下文窗口扩展16倍,适配多轮对话、长文摘要等场景。
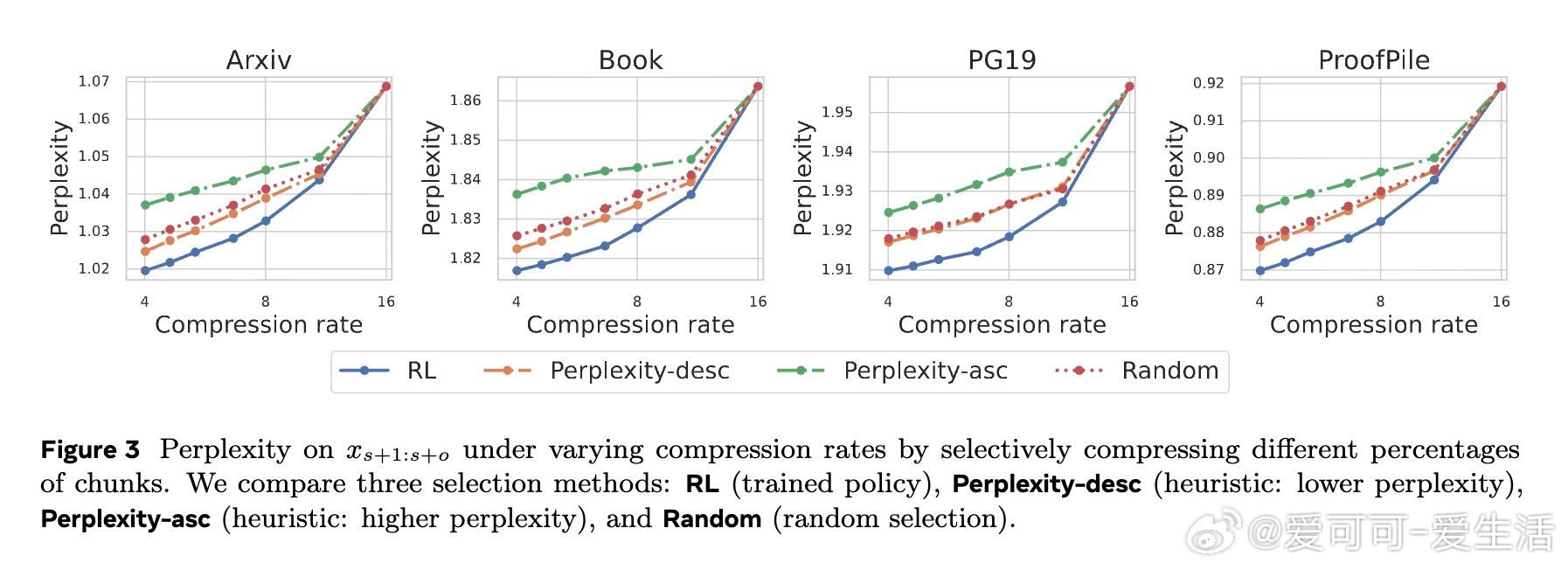
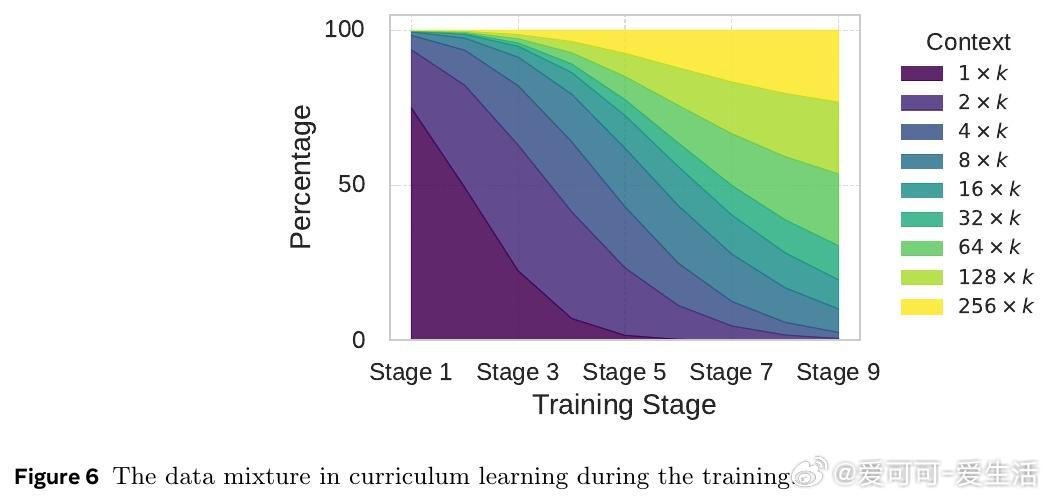
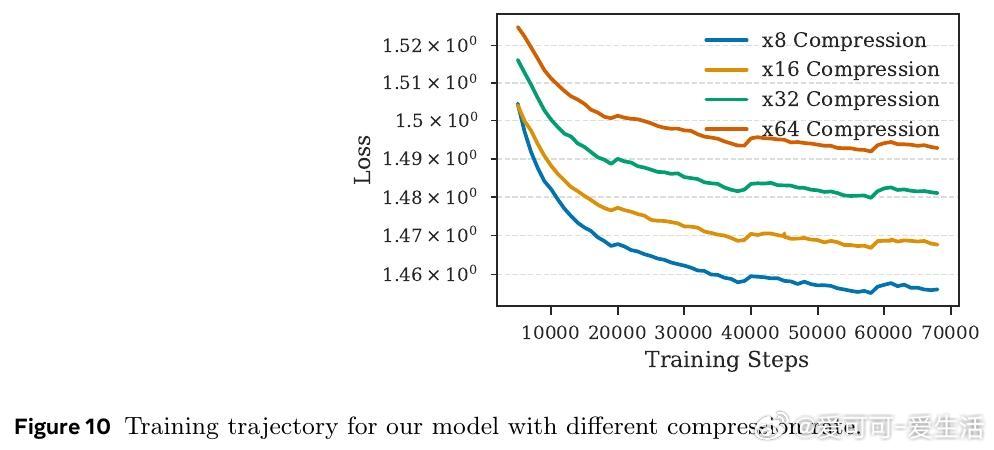
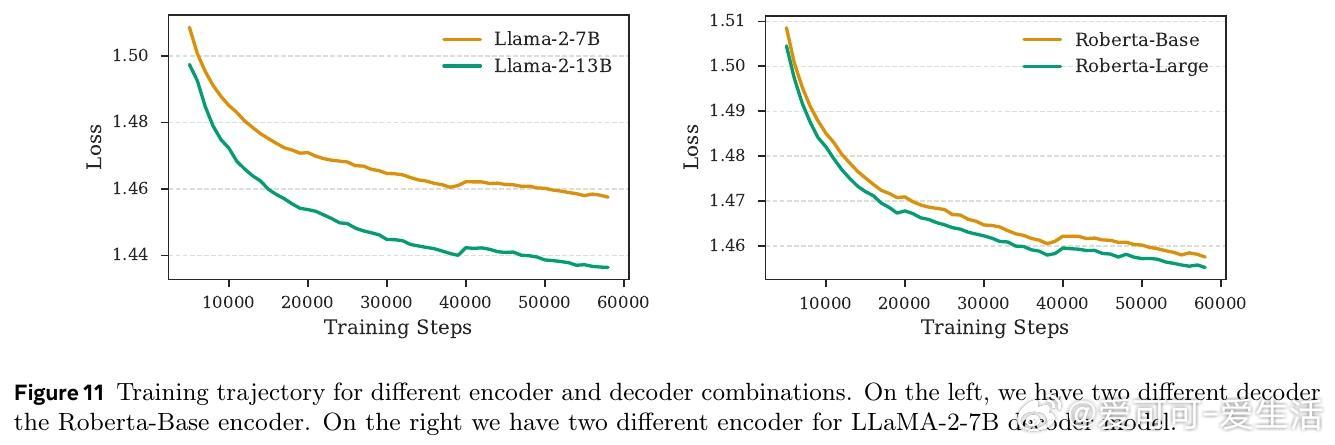
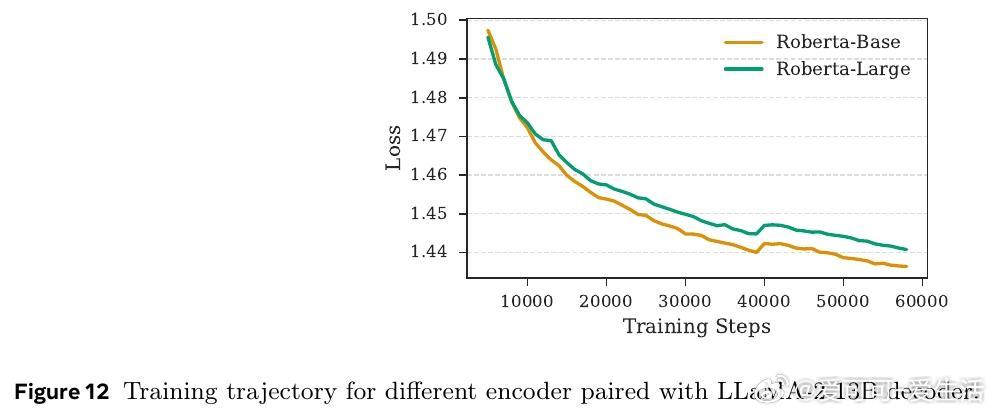
• 采用循序渐进的重建任务预训练,确保编码器与解码器对齐;结合强化学习优化压缩策略,在不同压缩率下均优于同等条件下的基线模型。
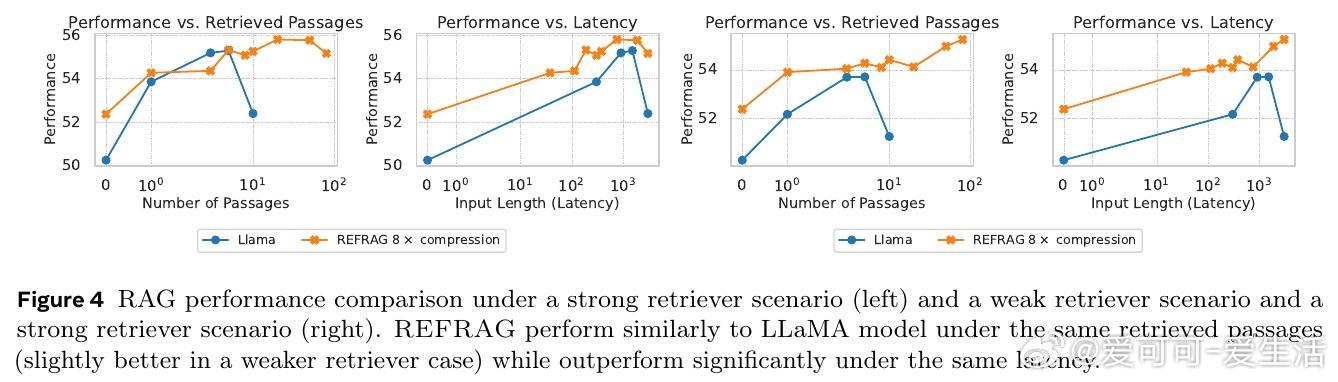
• 评测涵盖Arxiv、Book、PG19等多域长文本,及MMLU、BoolQ等知识密集型任务,验证泛化能力和实际应用价值。
心得:
1. RAG上下文的低语义相关性导致块状注意力结构,表明传统全token解码存在大量冗余计算,压缩chunk嵌入重构成为效率突破口。
2. 预计算并缓存chunk嵌入的设计,巧妙利用检索流程已有信息,避免重复编码,极大降低推理内存和计算负担。
3. 强化学习驱动的选择性压缩策略,动态权衡信息完整性与效率,是实现高压缩率同时保持性能的关键。
REFRAG为大规模知识增强LLM推理提供了切实可行的低延迟解决方案,推动多轮对话和长文本生成的实用化进程。
详情🔗 arxiv.org/abs/2509.01092
大语言模型检索增强生成长文本推理模型压缩强化学习