[CL]《Diffusion Language Models Know the Answer Before Decoding》P Li, Y Zhou, D Muhtar, L Yin... [The Hong Kong Polytechnic University & Dartmouth College & Max Planck Institute for Intelligent Systems] (2025)
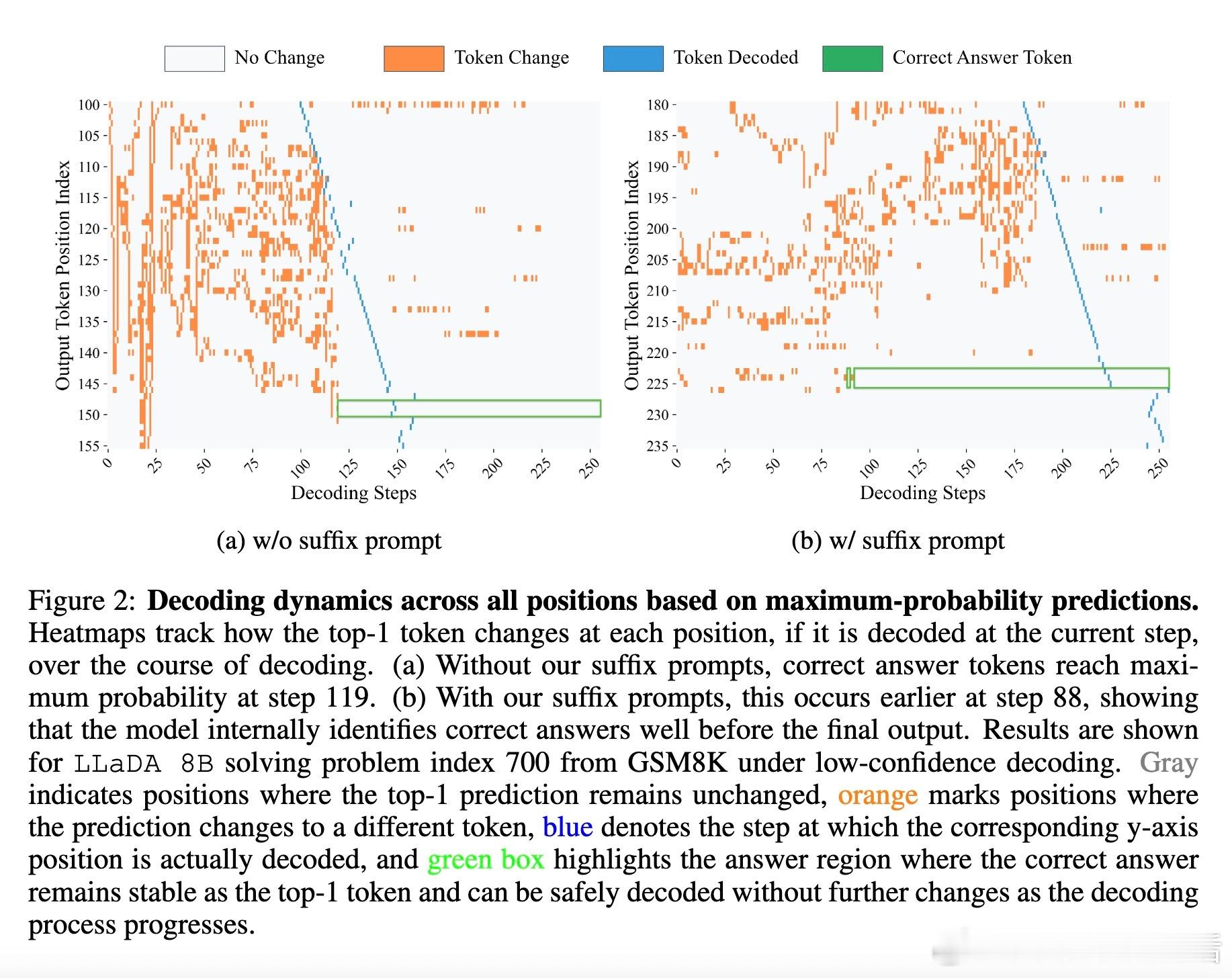
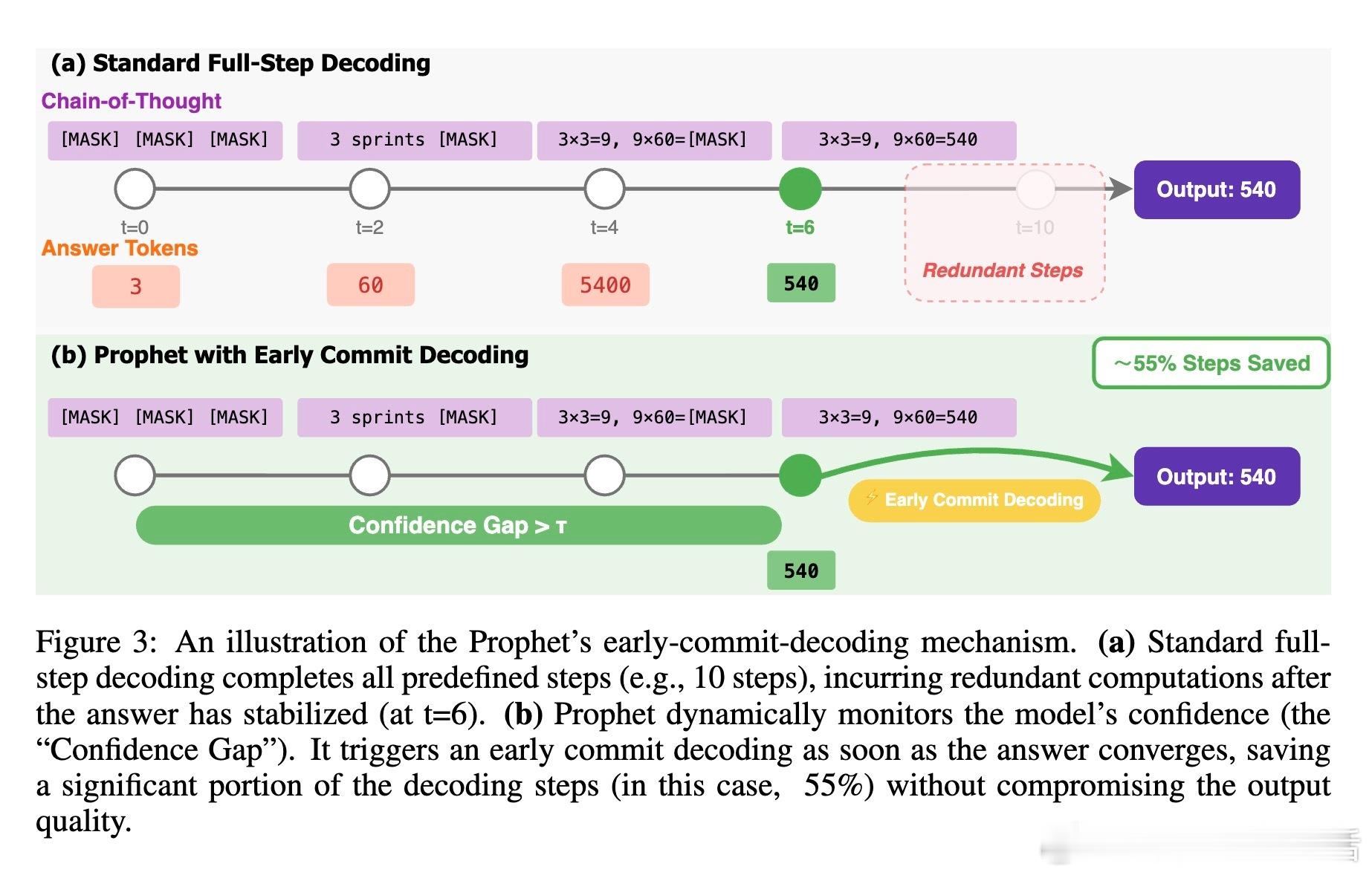
Diffusion Language Models(DLM)展现了“答案提前收敛”的重要特性:在多数情况下,模型在完成全部迭代步骤前即已内部确定正确答案。基于此,Prophet算法提出了一种无训练、动态调控的早期提交解码策略,利用预测中最高与次高候选的置信差作为判定标准,自动决定何时终止迭代,显著提升推理速度。
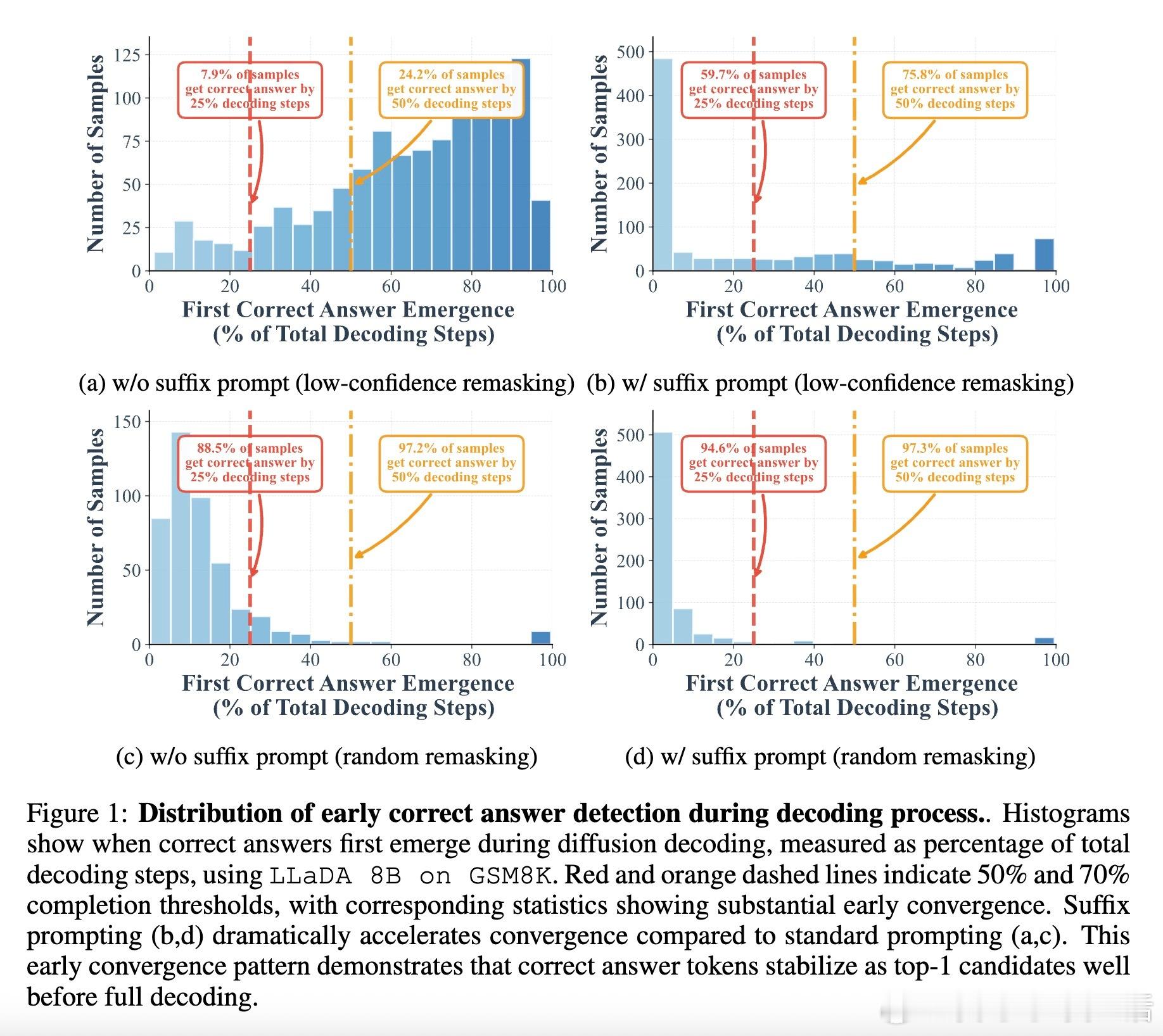
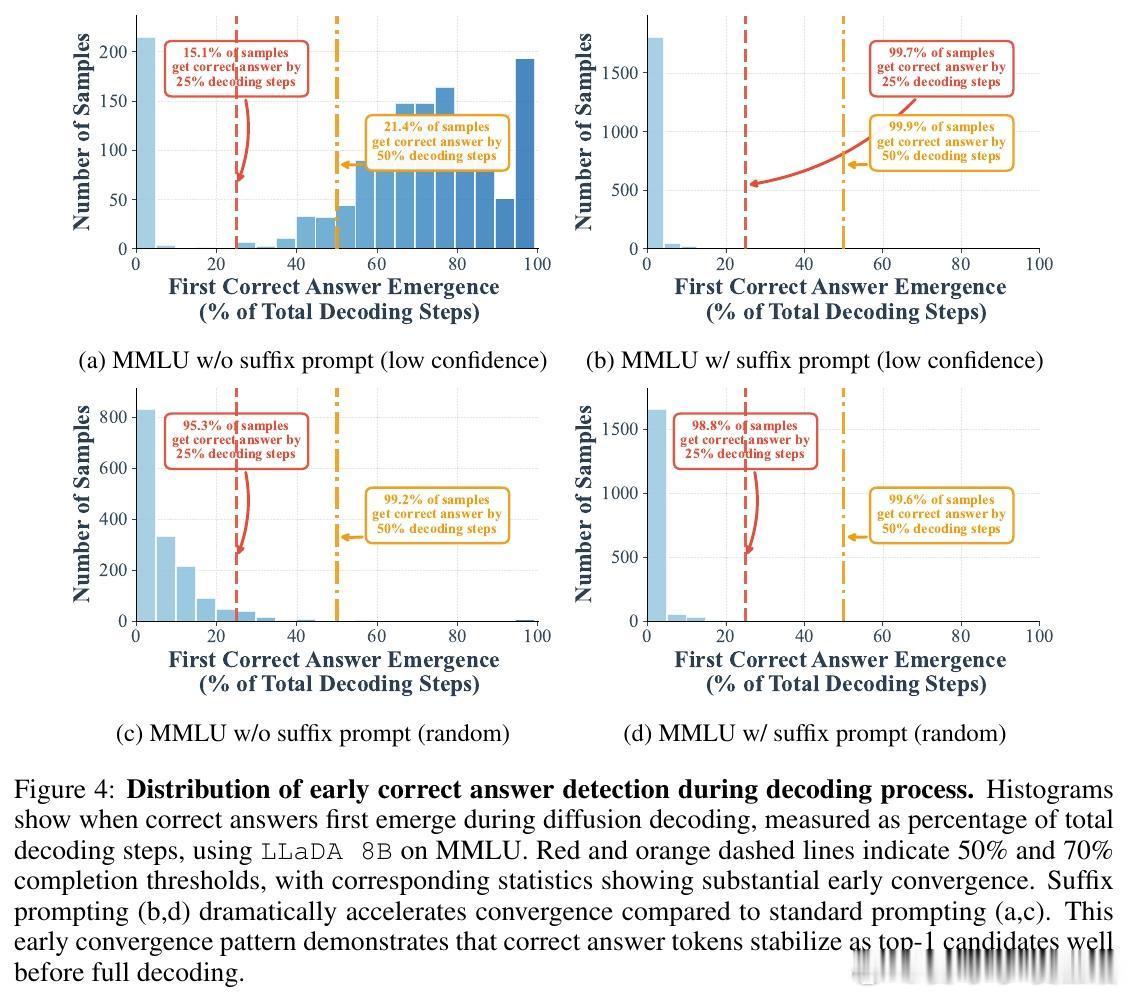
• 早期答案收敛现象:在GSM8K和MMLU数据集上,分别有高达97%与99%的样本可在半数迭代步骤内正确解码,表明传统全步迭代存在大量冗余计算。
• Prophet算法:无需额外训练,通过动态阈值调整实现“早期提交解码”,兼容现有DLM架构,计算开销极低。
• 显著加速:在LLaDA-8B和Dream-7B模型上,Prophet最高可减少3.4倍解码步骤,同时保持甚至提升生成质量,证明其在速度与准确率间实现优雅平衡。
• 方法论启示:将DLM解码视为最优停止问题,强调动态判断何时完成生成,突破了固定迭代次数的传统限制。
• 实验覆盖广泛任务,包括数学推理、通用问答和规划,均展现稳定效果。
该研究不仅揭示了DLM推理内部机制的本质,也为提升大规模语言模型效率提供了可操作路径,助力Diffusion模型更好地服务于实际应用场景。
详情阅读👉 arxiv.org/abs/2508.19982
扩散语言模型模型加速早期解码自然语言处理机器学习