[RO]《Exploiting Policy Idling for Dexterous Manipulation》A S. Chen, P Brakel, A Bronars, A Xie... [Google DeepMind] (2025)
机器人灵巧操作中的“政策停滞”现象与突破策略
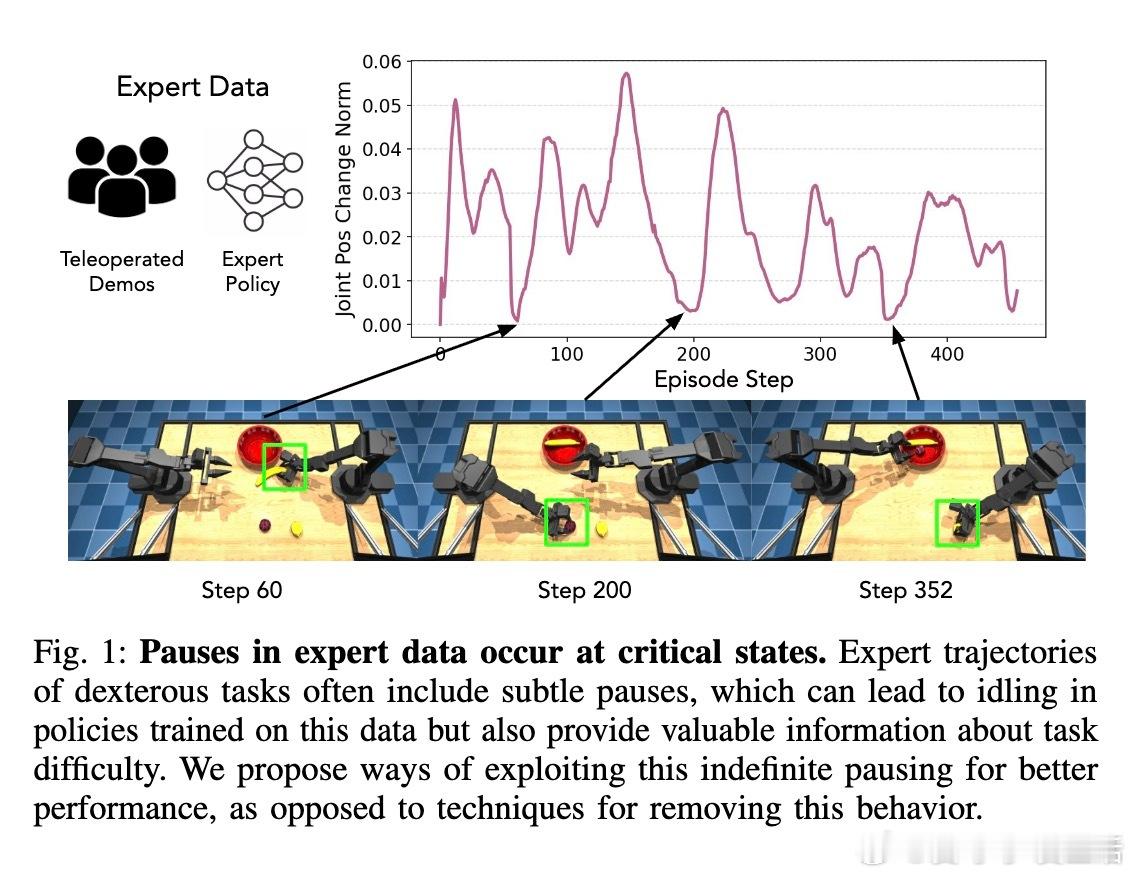
• 灵巧操作中,学习策略常在关键状态出现“停滞”——动作幅度极小、长时间停留,导致任务失败。这种停滞往往源自训练数据中微小动作的反复体现,尤其是在高精度操作前的准备阶段。
• 传统去除停滞的做法如过滤训练数据或延长控制步长,虽减少停滞但可能牺牲策略反应速度和精准度,且无法利用停滞信息提升性能。
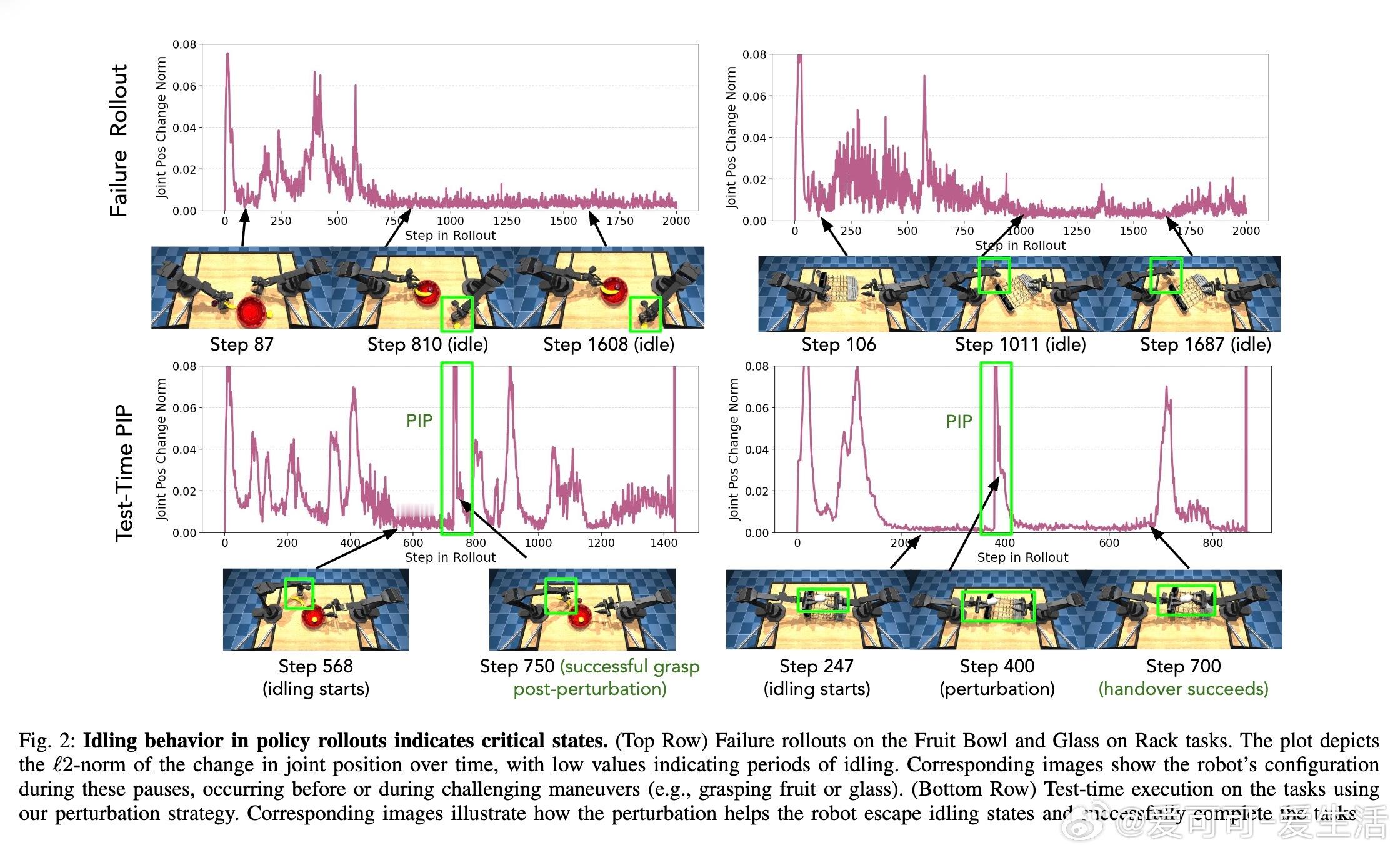
• 本文提出Pause-Induced Perturbations(PIP)方法:实时检测停滞状态,向策略动作施加适度干扰,将机器人动作向初始姿态插值,帮助策略跳出局部停滞态,促进探索与任务完成。
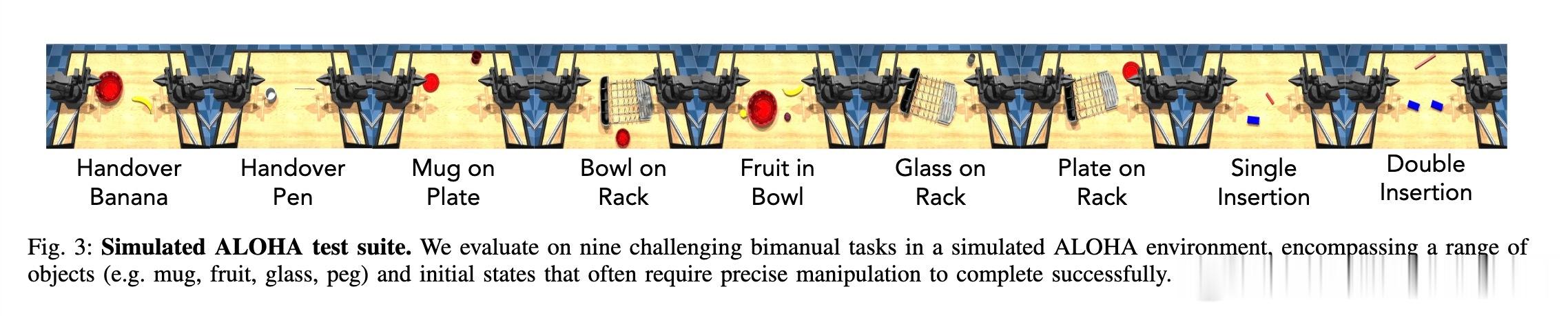
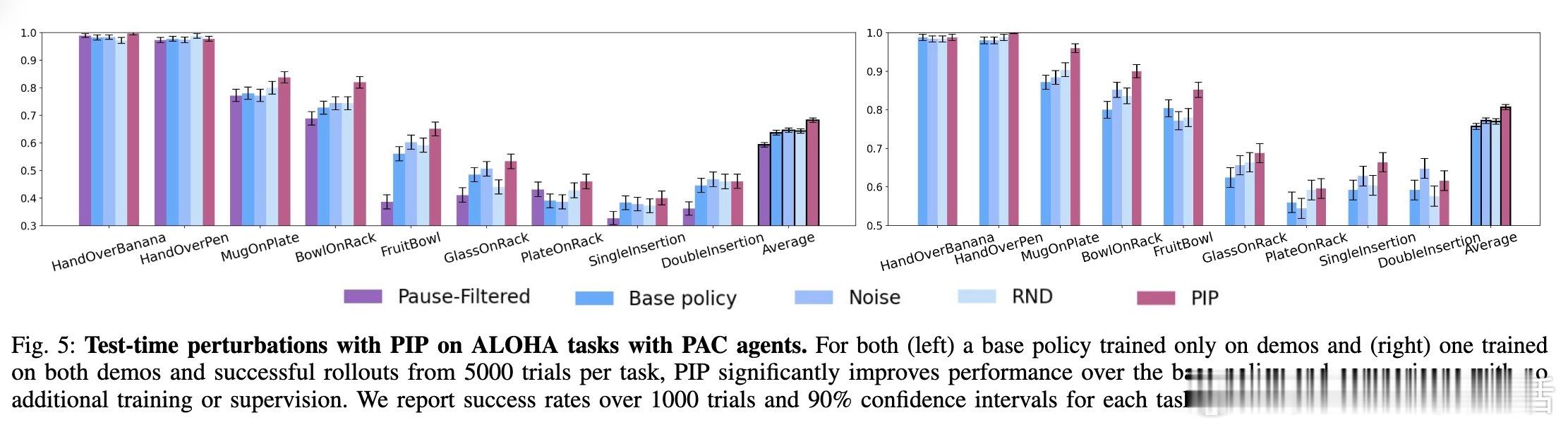
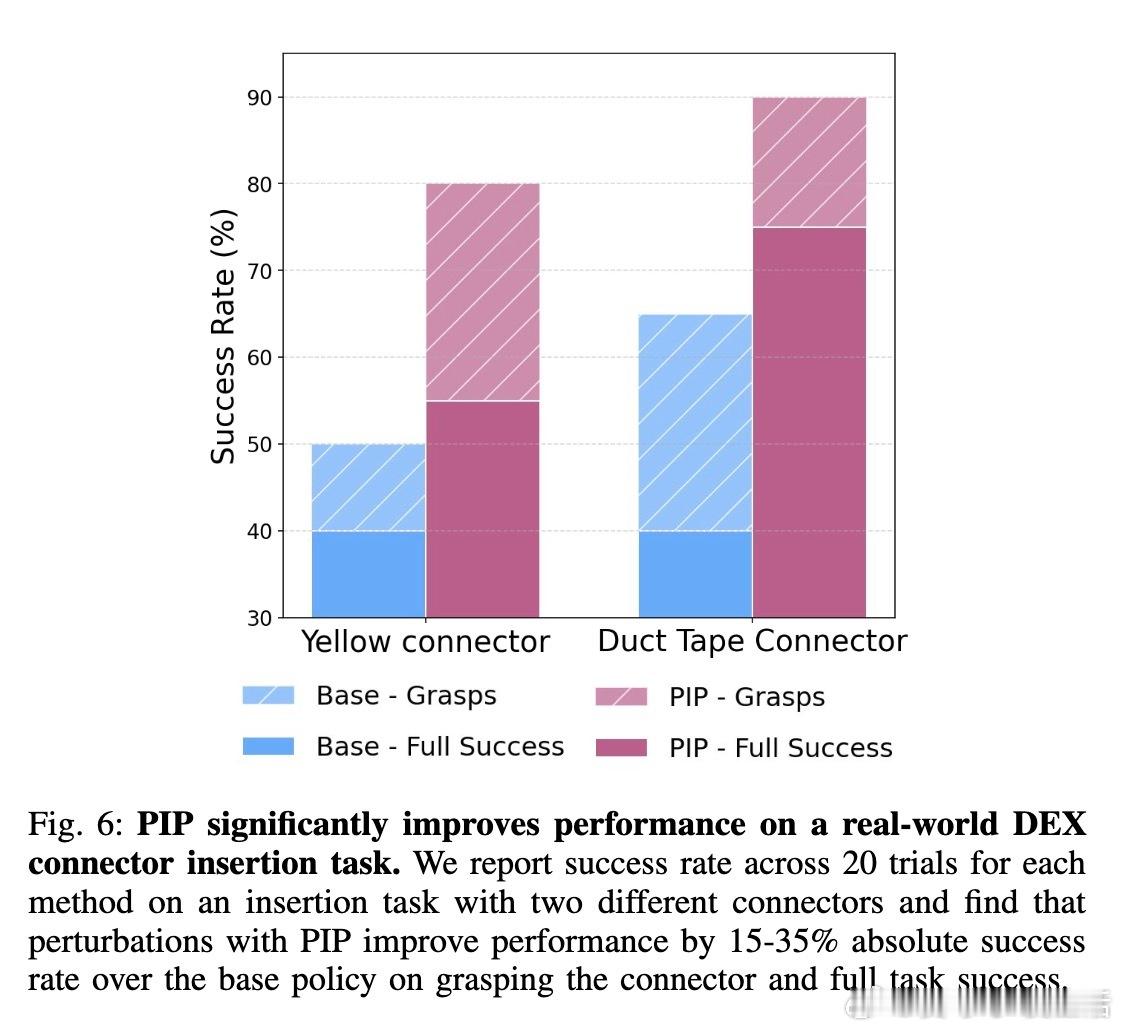
• PIP无需额外训练或监督,测试中即显著提升性能:模拟环境中成功率提升5-10%,真实机械手插入任务提升15-35%。
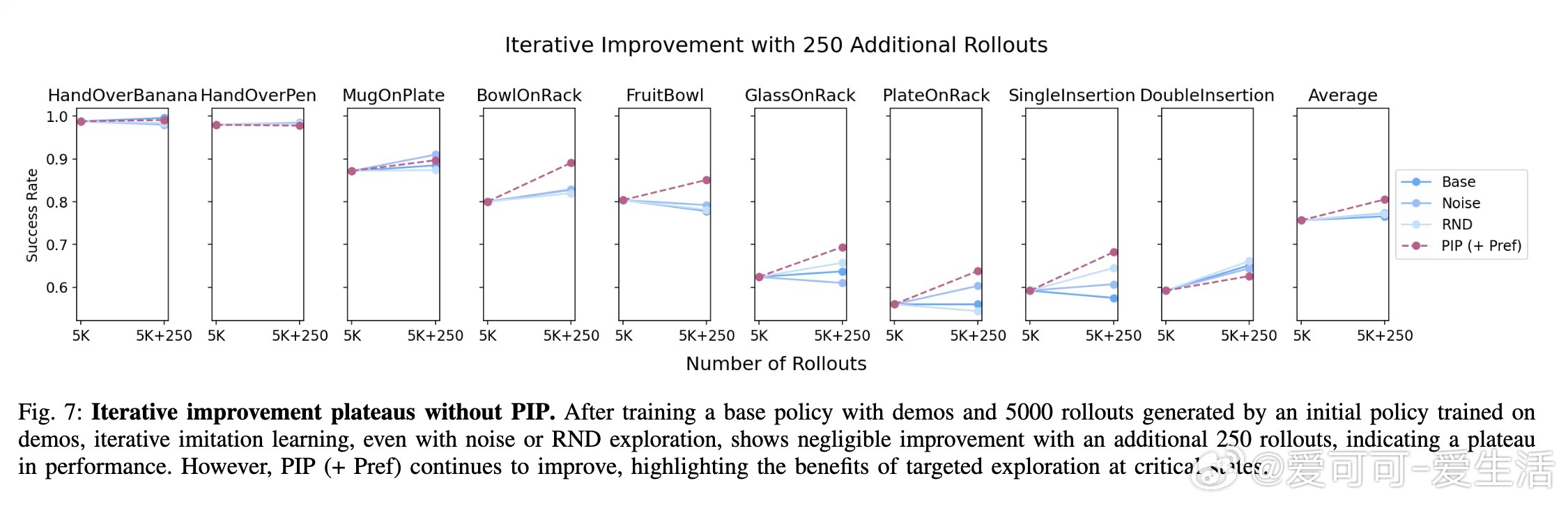
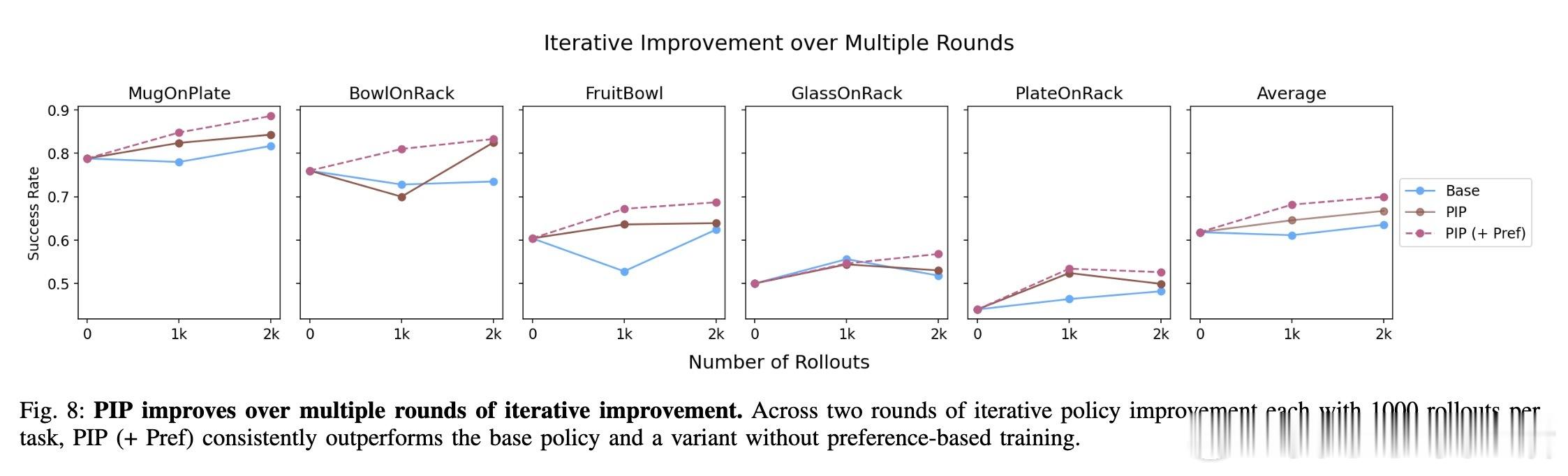
• 利用PIP产生的多样化轨迹数据,结合基于偏好的模仿学习,进一步减少导致停滞的失败动作,实现迭代自我提升,突破性能瓶颈。
• 多任务、多策略架构验证表明,停滞是普遍失败模式,针对性干扰策略能有效利用这一现象提升灵巧操作的鲁棒性和成功率。
• 该研究揭示:动作微小、停滞不仅是失败症状,更提供了识别任务难点和引导探索的内在信号,重新定义了如何看待和利用“停滞”现象。
深入理解“停滞”行为的本质及其时空分布,为灵巧操作策略设计提供了新视角和实用改进路径,推动机器人在复杂操作任务中的稳定性与精度提升。
详情阅读🔗arxiv.org/abs/2508.15669
机器人学强化学习灵巧操作模仿学习策略优化自我提升