[LG]《Reliable Unlearning Harmful Information in LLMs with Metamorphosis Representation Projection》C Wu, Z Wei, H Chen, Y Dong... [Peking University & Tsinghua University] (2025)
大语言模型(LLM)中的有害信息可靠“遗忘”迎来新突破:Metamorphosis Representation Projection(MRP)方法
• 传统参数微调手段难以彻底抹除模型中的不良知识,存在持续遗忘失败和“再学习”攻击风险。
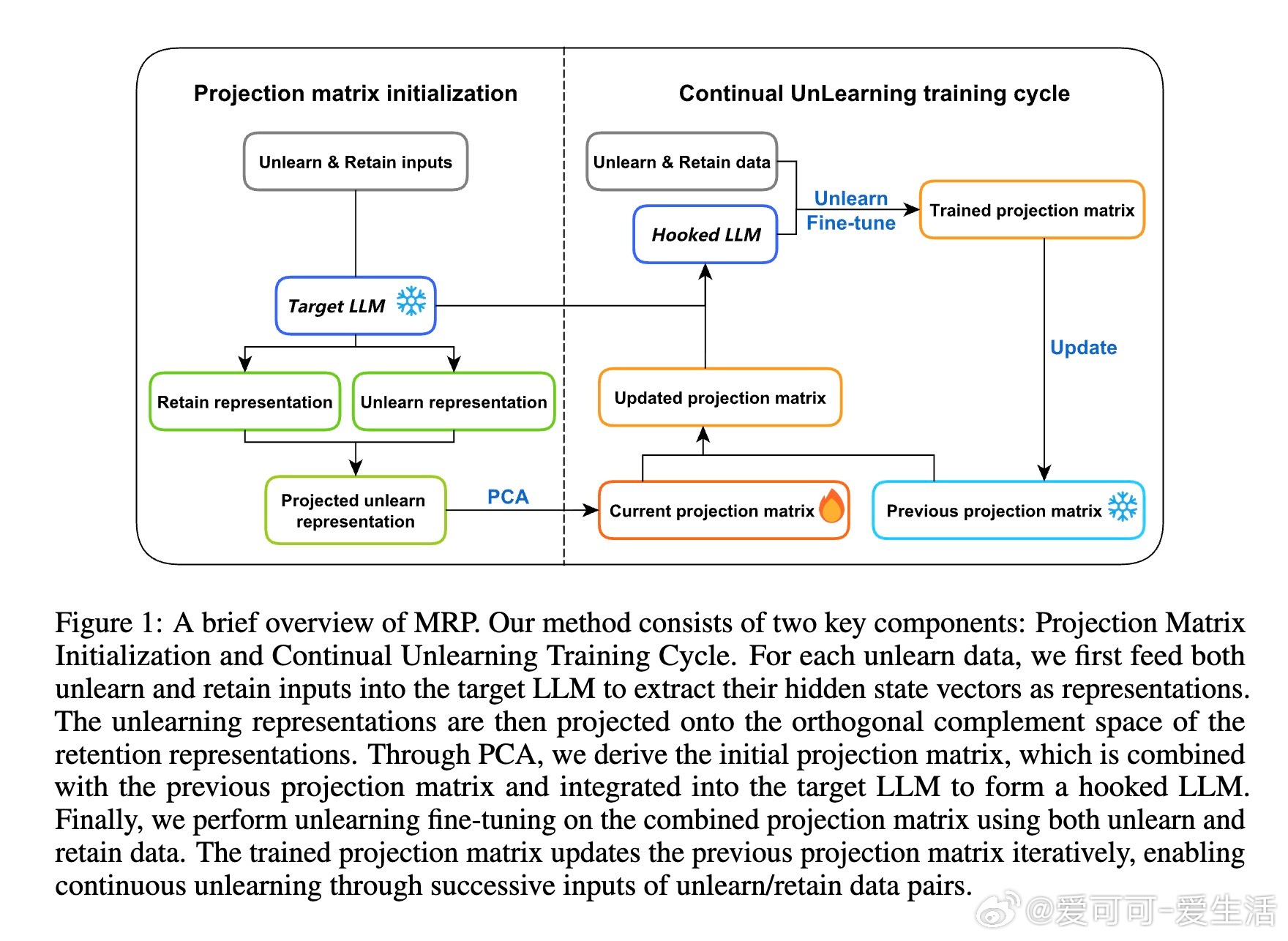
• MRP创新性地在特定网络层的隐藏状态空间施加不可逆投影,精准剔除目标任务信息,同时最大限度保留有用知识。
• 通过正交矩阵初始化和迭代更新投影矩阵,实现连续多轮遗忘而无灾难性遗忘,性能稳定且对抗再学习攻击能力强。
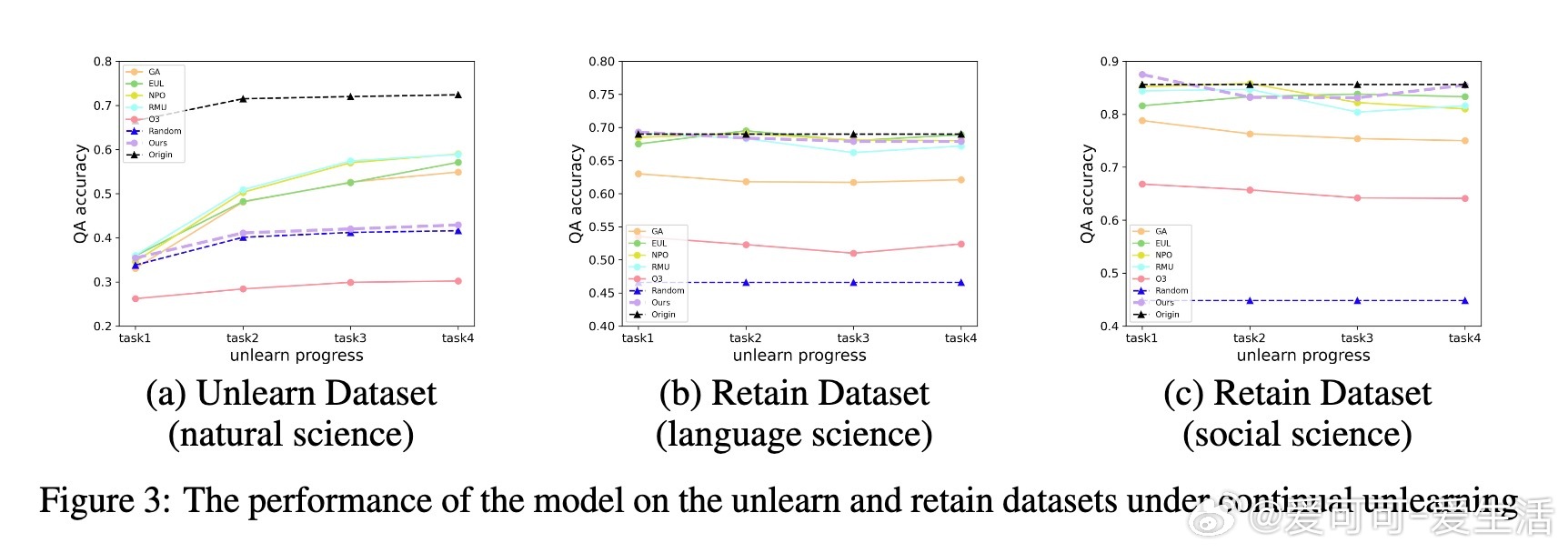
• 实验在LLaMA2-7B及Qwen-7B模型上展现领先表现:连续四任务遗忘后,遗忘效果评分达0.905,远超最佳基线0.785,并保持模型原有能力。
• 训练参数仅0.1M,计算效率高,适合资源受限环境。即使在缺乏完全保留数据集情况下,仍能利用相似数据保证遗忘与知识保留的平衡。
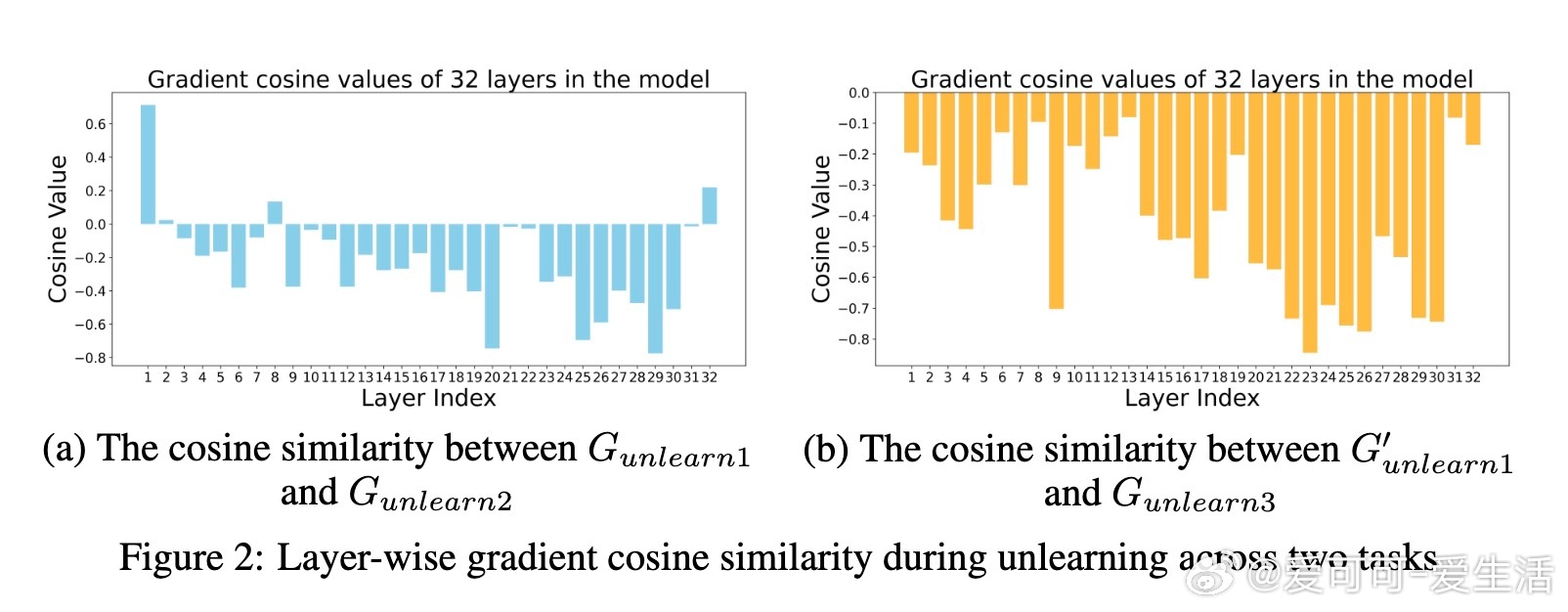
• 方法原理基于隐藏层低秩稀疏表示的正交投影,首次为LLM遗忘提出表示层面彻底剔除方案,开启模型安全治理新篇章。
详情阅读👉 arxiv.org/abs/2508.15449
大型语言模型机器遗忘模型安全连续学习人工智能安全