为何人类能制造超级计算机,却无法创造最简单的细胞?
为何人类能制造超级计算机,却无法创造最简单的细胞?
有了这种独特的优势,即作为地球上已知的唯一拥有超强智慧的物种,我们人类只用了几百万年(而地球历史上有45.5亿年)就完全摆脱了自然选择的限制,在地球上创造了辉煌的文明。随着技术的不断进步,现代人类可以上天入海,甚至在遥远的火星上也有人类探测器。我们取得目前成就的最重要原因之一是我们有能力创造出各种各样的人工制品,使我们的能力大幅提高,而在这些人工制品中,超级计算机是人工制品的顶峰。最好的超级计算机每秒可以进行20亿次浮点运算,过去需要数十年甚至数百年才能计算出来的东西可以在一秒钟内完成。

几十亿甚至几百亿的晶体管集中在一个CPU中,每个都是精心设计的实体,具有确定的功能,而一台超级计算机有成千上万个这样的CPU,难怪超级计算机的计算能力如此强大。作为人类,我们为能够建造如此复杂和精密的工具而自豪,但相当尴尬的是,我们人类在生命科学方面的水平如此之低,事实上,我们甚至不能建造最简单的细胞。为什么人类可以建造超级计算机,却不能建造最简单的细胞?对于这个问题,我们似乎可以给出一个简单的答案,那就是细胞是生命的基本组成部分,即使是最简单的细胞,其微观结构也相当复杂,以人类目前的能力,不可能知道其所有的奥秘,但实际上并不完全是这样,因为要制造一个细胞,除了要充分了解其微观结构外,还有一个巨大的难题,下面我们将以人类细胞的DNA为例进行说明。

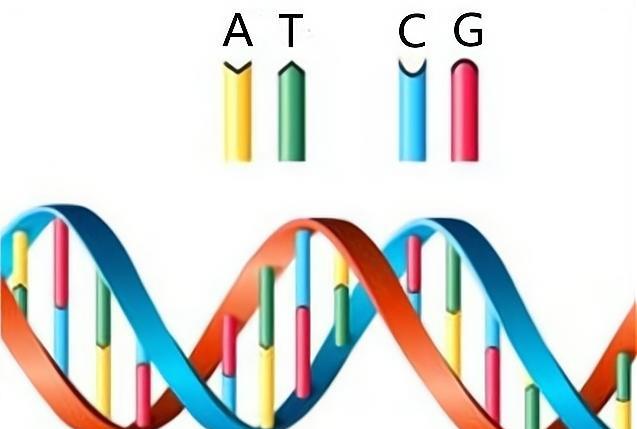
DNA本质上是一种由脱氧核糖、磷酸盐和大量碱基组成的大型聚合物,但只有四种碱基,即腺嘌呤(A)、鸟嘌呤(G)、胸腺嘧啶(T)和胞嘧啶(C)。这四种碱基不断变化,记录着生命和进化的奥秘。因此,DNA实际上是一个由四个符号组成的特殊代码:A、G、T和C。这个代码有多复杂?科学家告诉我们,人类的DNA中大约有30亿对这样的符号,这听起来很复杂,但就数据而言,它只是几个Gb的数据。以超级计算机的威力,要弄清楚这么多的数据是很容易的,但问题是,即使有DNA代码在我们面前,也要花很长很长的时间才能弄清楚它是怎么回事。
以计算机系统为例。我们的计算机系统实际上只知道0和1,所有在其上运行的高级程序都必须被翻译成由0和1组成的机器语言,才能被计算机运行。同样,计算机运行程序的结果也是由0和1组成的,我们需要对它们进行编译以得到我们可以理解的结果。既然我们知道计算机如何工作,如何编译,如何运行,甚至知道程序中的每个0和1代表什么,我们就可以按照从简单到复杂的步骤,设计出强大的超级计算机系统,可以用来操作大量的0和1来运行复杂的程序。

想象一下,如果我们面对大量的0和1,而我们又没有编译的知识,我们能够知道这个程序是如何运行的吗?显而易见的答案是,我们需要很长很长的时间来了解隐藏在这堆0和1中的东西。事实是,我们现在面对的是一堆由A、G、T和C四个符号组成的 生命代码,但我们必须从头开始理解它们。我们已经观察到许多现象,积累了大量的数据,但我们还没能总结出完美的规律,这就是为什么我们甚至还没能创造出最简单的细胞。当然,这一定只是暂时的情况,我相信凭借人类的聪明才智,有一天我们将能够理解生命的所有奥秘。